Αναζήτηση στην κοινότητα
Εμφάνιση αποτελεσμάτων για τις ετικέτες 'τεχνητή νοημοσύνη'.
181 αποτελέσματα
-

Πρόωρη κινδυνεύει να αποδειχτεί η κυκλοφορία του Grok
Snoob δημοσίευσε ένα άρθρο στο Artificial Intelligence
 Το chatbot του Χ υποτίθεται πως είναι ένα μοντέλο τεχνητής νοημοσύνης το οποίο αξιοποιεί τις αναρτήσεις στην πλατφόρμα κοινωνικής δικτύωσης, προκειμένου να εμφανίζει περιλήψεις των τελευταίων ειδήσεων, όμως στην εβδομάδα που μας πέρασε οι αδυναμίες του Grok αποκαλύφθηκαν για πολλοστή φορά, όταν το chatbot μπερδεύτηκε και αδίκως κατηγόρησε αστέρα του ΝΒΑ για βανδαλισμό. "Ο Κλέι Τόμσον κατηγορείται για σειρά επιθέσεων με τούβλα", ανέφερε ο τίτλος που σχημάτισε το Grok σε ανάρτηση που παρέμεινε κανονικά στη θέση της στο Χ για ημέρες. Κάτω από τον τίτλο, το Grok προχωρούσε σε λεπτομέρειες, για να αναλύσει την πλαστή είδηση: "Σε μια αλλόκοτη εξέλιξη, ο Κλέι Τόμσον, αστέρας του ΝΒΑ, κατηγορείται πως βανδάλισε πολλά σπίτια με τούβλα στο Σακραμέντο. Οι αρχές ερευνούν την υπόθεση καθώς διάφορα άτομα ισχυρίζονται ότι τα σπίτια τους υπέστησαν ζημιές, με τα παράθυρα να θρυμματίζονται από τούβλα. Ο Κλέι Τόμσον δεν έχει προβεί ακόμη σε κάποια δήλωση σχετικά με τις κατηγορίες αυτές. Τα περιστατικά έχουν ταράξει την τοπική κοινότητα, όμως δεν έχουν αναφερθεί τραυματισμοί. Το κίνητρο πίσω από τον ανεπιβεβαίωτο βανδαλισμό παραμένει ασαφές". Το Grok προφανώς συγχέει ένα συνήθη όρο στο μπάσκετ, όπου οι παίκτες κατηγορούνται ότι εξαπολύουν "τούβλα" όταν σουτάρουν εντελώς άστοχα. Σύμφωνα με την ιστοσελίδα SF Gate, από τις πρώτες που εντόπισαν το σφάλμα του Grok, ο Τόμσον είχε μια συνολικά δύσκολη αγωνιστική βραδιά, καθώς δεν ευστόχησε σε κανένα από τα σουτ που επιχείρησε, στο συναισθηματικά φορτισμένο τελευταίο παιχνίδι του με τους Golden State Warriors, προτού μείνει ελεύθερος να διαπραγματευτεί τον επόμενο σταθμό της καριέρας του. Με ψιλά γράμματα κάτω από την είδηση που ανάρτησε το Grok, υπάρχει και μια δήλωση αποποίησης ευθυνών, που αναφέρει ότι "το Grok βρίσκεται σε πρώιμο στάδιο και μπορεί να κάνει λάθη. Επιβεβαιώστε την ακρίβεια των αναρτήσεών του". Όμως, αντί να επιβεβαιώσουν την ακρίβεια της συγκεκριμένης ανάρτησης, ορισμένοι χρήστες επέλεξαν να ενισχύσουν την παραπληροφόρηση. Κάτω από την ανάρτηση του chatbot, εμφανίστηκαν δηλώσεις δήθεν θυμάτων. Ορισμένα από αυτά τα χιουμοριστικά μηνύματα κατέγραψαν εκατομμύρια εμφανίσεις. Στο παρελθόν, τόσο η Microsoft όσο και η OpenAI έχουν έρθει αντιμέτωπες με μηνύσεις για συκοφαντική δυσφήμιση, καθώς το ChatGPT είχε κατηγορήσει αβάσιμα έναν πολιτικό και ένα ραδιοφωνικό παραγωγό για εντελώς πλαστές εγκληματικές ενέργειες. Η Microsoft μηνύθηκε επίσης από έναν καθηγητή αεροναυπηγικής, τον οποίο το Bing Chat ψευδώς χαρακτήρισε τρομοκράτη. Ασαφές παραμένει το κατά πόσο μια δήλωση αποποίησης, όπως αυτή που εμφανίζεται κάτω από το Grok, θα επιτρέψει στις εταιρίες που προωθούν αυτά τα προϊόντα να αποφύγουν τις νομικές συνέπειες, σε περίπτωση που αποφασίσει κάποιος να κινηθεί εναντίον τους. Ενδεχομένως, το κατά πόσο υπήρξε δυσφήμιση να κριθεί από το αν μπορεί να αποδειχτεί ότι οι πλατφόρμες "εν γνώσει τους" δημοσιεύουν πλαστές πληροφορίες. Η πλαστή είδηση με τους δήθεν βανδαλισμούς του Τόμσον μπορεί να είναι η πρώτη περίπτωση όπου μια αστοχία του Grok γίνεται ευρύτερα γνωστή, όμως δεν ήταν η πρώτη φορά που το Grok διακινούσε ασυναρτησίες, πατώντας σε αναρτήσεις χρηστών του Χ που αστειεύονταν στην πλατφόρμα. Στη διάρκεια της πρόσφατης έκλειψης ηλίου, λόγου χάρη, σύμφωνα με ρεπορτάζ του Gizmodo, το Grok ανάρτησε τίτλο που ανέφερε "Η Αλλόκοτη Συμπεριφορά του Ήλιου: Απορούν οι Ειδικοί". Παρότι είναι διασκεδαστικό να βλέπει κανείς τους χρήστες να σπάνε πλάκα με το Grok, η όλη κατάσταση φανερώνει ότι το Grok ενδέχεται να αποδειχτεί ευάλωτο στη χειραγώγηση από κακόβουλος παράγοντες, ώστε να προωθήσει σοβαρότερες πλαστές ή προπαγανδιστικές ειδήσεις. Οι δυνατότητες των μοντέλων τεχνητής νοημοσύνης παραμένουν εντυπωσιακές, όμως αυξάνεται η ανησυχία για την ποιότητα των δεδομένων με τα οποία εκπαιδεύονται και το περιστατικό με το Grok και τα "τούβλα" του Κλέι Τόμσον έρχεται να προστεθεί σε μια σειρά ανάλογων καταστάσεων όπου τα chatbots αναπαράγουν εντελώς λανθασμένα αποτελέσματα.
Το chatbot του Χ υποτίθεται πως είναι ένα μοντέλο τεχνητής νοημοσύνης το οποίο αξιοποιεί τις αναρτήσεις στην πλατφόρμα κοινωνικής δικτύωσης, προκειμένου να εμφανίζει περιλήψεις των τελευταίων ειδήσεων, όμως στην εβδομάδα που μας πέρασε οι αδυναμίες του Grok αποκαλύφθηκαν για πολλοστή φορά, όταν το chatbot μπερδεύτηκε και αδίκως κατηγόρησε αστέρα του ΝΒΑ για βανδαλισμό. "Ο Κλέι Τόμσον κατηγορείται για σειρά επιθέσεων με τούβλα", ανέφερε ο τίτλος που σχημάτισε το Grok σε ανάρτηση που παρέμεινε κανονικά στη θέση της στο Χ για ημέρες. Κάτω από τον τίτλο, το Grok προχωρούσε σε λεπτομέρειες, για να αναλύσει την πλαστή είδηση: "Σε μια αλλόκοτη εξέλιξη, ο Κλέι Τόμσον, αστέρας του ΝΒΑ, κατηγορείται πως βανδάλισε πολλά σπίτια με τούβλα στο Σακραμέντο. Οι αρχές ερευνούν την υπόθεση καθώς διάφορα άτομα ισχυρίζονται ότι τα σπίτια τους υπέστησαν ζημιές, με τα παράθυρα να θρυμματίζονται από τούβλα. Ο Κλέι Τόμσον δεν έχει προβεί ακόμη σε κάποια δήλωση σχετικά με τις κατηγορίες αυτές. Τα περιστατικά έχουν ταράξει την τοπική κοινότητα, όμως δεν έχουν αναφερθεί τραυματισμοί. Το κίνητρο πίσω από τον ανεπιβεβαίωτο βανδαλισμό παραμένει ασαφές". Το Grok προφανώς συγχέει ένα συνήθη όρο στο μπάσκετ, όπου οι παίκτες κατηγορούνται ότι εξαπολύουν "τούβλα" όταν σουτάρουν εντελώς άστοχα. Σύμφωνα με την ιστοσελίδα SF Gate, από τις πρώτες που εντόπισαν το σφάλμα του Grok, ο Τόμσον είχε μια συνολικά δύσκολη αγωνιστική βραδιά, καθώς δεν ευστόχησε σε κανένα από τα σουτ που επιχείρησε, στο συναισθηματικά φορτισμένο τελευταίο παιχνίδι του με τους Golden State Warriors, προτού μείνει ελεύθερος να διαπραγματευτεί τον επόμενο σταθμό της καριέρας του. Με ψιλά γράμματα κάτω από την είδηση που ανάρτησε το Grok, υπάρχει και μια δήλωση αποποίησης ευθυνών, που αναφέρει ότι "το Grok βρίσκεται σε πρώιμο στάδιο και μπορεί να κάνει λάθη. Επιβεβαιώστε την ακρίβεια των αναρτήσεών του". Όμως, αντί να επιβεβαιώσουν την ακρίβεια της συγκεκριμένης ανάρτησης, ορισμένοι χρήστες επέλεξαν να ενισχύσουν την παραπληροφόρηση. Κάτω από την ανάρτηση του chatbot, εμφανίστηκαν δηλώσεις δήθεν θυμάτων. Ορισμένα από αυτά τα χιουμοριστικά μηνύματα κατέγραψαν εκατομμύρια εμφανίσεις. Στο παρελθόν, τόσο η Microsoft όσο και η OpenAI έχουν έρθει αντιμέτωπες με μηνύσεις για συκοφαντική δυσφήμιση, καθώς το ChatGPT είχε κατηγορήσει αβάσιμα έναν πολιτικό και ένα ραδιοφωνικό παραγωγό για εντελώς πλαστές εγκληματικές ενέργειες. Η Microsoft μηνύθηκε επίσης από έναν καθηγητή αεροναυπηγικής, τον οποίο το Bing Chat ψευδώς χαρακτήρισε τρομοκράτη. Ασαφές παραμένει το κατά πόσο μια δήλωση αποποίησης, όπως αυτή που εμφανίζεται κάτω από το Grok, θα επιτρέψει στις εταιρίες που προωθούν αυτά τα προϊόντα να αποφύγουν τις νομικές συνέπειες, σε περίπτωση που αποφασίσει κάποιος να κινηθεί εναντίον τους. Ενδεχομένως, το κατά πόσο υπήρξε δυσφήμιση να κριθεί από το αν μπορεί να αποδειχτεί ότι οι πλατφόρμες "εν γνώσει τους" δημοσιεύουν πλαστές πληροφορίες. Η πλαστή είδηση με τους δήθεν βανδαλισμούς του Τόμσον μπορεί να είναι η πρώτη περίπτωση όπου μια αστοχία του Grok γίνεται ευρύτερα γνωστή, όμως δεν ήταν η πρώτη φορά που το Grok διακινούσε ασυναρτησίες, πατώντας σε αναρτήσεις χρηστών του Χ που αστειεύονταν στην πλατφόρμα. Στη διάρκεια της πρόσφατης έκλειψης ηλίου, λόγου χάρη, σύμφωνα με ρεπορτάζ του Gizmodo, το Grok ανάρτησε τίτλο που ανέφερε "Η Αλλόκοτη Συμπεριφορά του Ήλιου: Απορούν οι Ειδικοί". Παρότι είναι διασκεδαστικό να βλέπει κανείς τους χρήστες να σπάνε πλάκα με το Grok, η όλη κατάσταση φανερώνει ότι το Grok ενδέχεται να αποδειχτεί ευάλωτο στη χειραγώγηση από κακόβουλος παράγοντες, ώστε να προωθήσει σοβαρότερες πλαστές ή προπαγανδιστικές ειδήσεις. Οι δυνατότητες των μοντέλων τεχνητής νοημοσύνης παραμένουν εντυπωσιακές, όμως αυξάνεται η ανησυχία για την ποιότητα των δεδομένων με τα οποία εκπαιδεύονται και το περιστατικό με το Grok και τα "τούβλα" του Κλέι Τόμσον έρχεται να προστεθεί σε μια σειρά ανάλογων καταστάσεων όπου τα chatbots αναπαράγουν εντελώς λανθασμένα αποτελέσματα. -
Eπιμένει να εμφανίζει πλαστές ειδήσεις το Grok, βασισμένο σε αστεία που κάνουν μεταξύ τους οι χρήστες του Χ. Το chatbot του Χ υποτίθεται πως είναι ένα μοντέλο τεχνητής νοημοσύνης το οποίο αξιοποιεί τις αναρτήσεις στην πλατφόρμα κοινωνικής δικτύωσης, προκειμένου να εμφανίζει περιλήψεις των τελευταίων ειδήσεων, όμως στην εβδομάδα που μας πέρασε οι αδυναμίες του Grok αποκαλύφθηκαν για πολλοστή φορά, όταν το chatbot μπερδεύτηκε και αδίκως κατηγόρησε αστέρα του ΝΒΑ για βανδαλισμό. "Ο Κλέι Τόμσον κατηγορείται για σειρά επιθέσεων με τούβλα", ανέφερε ο τίτλος που σχημάτισε το Grok σε ανάρτηση που παρέμεινε κανονικά στη θέση της στο Χ για ημέρες. Κάτω από τον τίτλο, το Grok προχωρούσε σε λεπτομέρειες, για να αναλύσει την πλαστή είδηση: "Σε μια αλλόκοτη εξέλιξη, ο Κλέι Τόμσον, αστέρας του ΝΒΑ, κατηγορείται πως βανδάλισε πολλά σπίτια με τούβλα στο Σακραμέντο. Οι αρχές ερευνούν την υπόθεση καθώς διάφορα άτομα ισχυρίζονται ότι τα σπίτια τους υπέστησαν ζημιές, με τα παράθυρα να θρυμματίζονται από τούβλα. Ο Κλέι Τόμσον δεν έχει προβεί ακόμη σε κάποια δήλωση σχετικά με τις κατηγορίες αυτές. Τα περιστατικά έχουν ταράξει την τοπική κοινότητα, όμως δεν έχουν αναφερθεί τραυματισμοί. Το κίνητρο πίσω από τον ανεπιβεβαίωτο βανδαλισμό παραμένει ασαφές". Το Grok προφανώς συγχέει ένα συνήθη όρο στο μπάσκετ, όπου οι παίκτες κατηγορούνται ότι εξαπολύουν "τούβλα" όταν σουτάρουν εντελώς άστοχα. Σύμφωνα με την ιστοσελίδα SF Gate, από τις πρώτες που εντόπισαν το σφάλμα του Grok, ο Τόμσον είχε μια συνολικά δύσκολη αγωνιστική βραδιά, καθώς δεν ευστόχησε σε κανένα από τα σουτ που επιχείρησε, στο συναισθηματικά φορτισμένο τελευταίο παιχνίδι του με τους Golden State Warriors, προτού μείνει ελεύθερος να διαπραγματευτεί τον επόμενο σταθμό της καριέρας του. Με ψιλά γράμματα κάτω από την είδηση που ανάρτησε το Grok, υπάρχει και μια δήλωση αποποίησης ευθυνών, που αναφέρει ότι "το Grok βρίσκεται σε πρώιμο στάδιο και μπορεί να κάνει λάθη. Επιβεβαιώστε την ακρίβεια των αναρτήσεών του". Όμως, αντί να επιβεβαιώσουν την ακρίβεια της συγκεκριμένης ανάρτησης, ορισμένοι χρήστες επέλεξαν να ενισχύσουν την παραπληροφόρηση. Κάτω από την ανάρτηση του chatbot, εμφανίστηκαν δηλώσεις δήθεν θυμάτων. Ορισμένα από αυτά τα χιουμοριστικά μηνύματα κατέγραψαν εκατομμύρια εμφανίσεις. Στο παρελθόν, τόσο η Microsoft όσο και η OpenAI έχουν έρθει αντιμέτωπες με μηνύσεις για συκοφαντική δυσφήμιση, καθώς το ChatGPT είχε κατηγορήσει αβάσιμα έναν πολιτικό και ένα ραδιοφωνικό παραγωγό για εντελώς πλαστές εγκληματικές ενέργειες. Η Microsoft μηνύθηκε επίσης από έναν καθηγητή αεροναυπηγικής, τον οποίο το Bing Chat ψευδώς χαρακτήρισε τρομοκράτη. Ασαφές παραμένει το κατά πόσο μια δήλωση αποποίησης, όπως αυτή που εμφανίζεται κάτω από το Grok, θα επιτρέψει στις εταιρίες που προωθούν αυτά τα προϊόντα να αποφύγουν τις νομικές συνέπειες, σε περίπτωση που αποφασίσει κάποιος να κινηθεί εναντίον τους. Ενδεχομένως, το κατά πόσο υπήρξε δυσφήμιση να κριθεί από το αν μπορεί να αποδειχτεί ότι οι πλατφόρμες "εν γνώσει τους" δημοσιεύουν πλαστές πληροφορίες. Η πλαστή είδηση με τους δήθεν βανδαλισμούς του Τόμσον μπορεί να είναι η πρώτη περίπτωση όπου μια αστοχία του Grok γίνεται ευρύτερα γνωστή, όμως δεν ήταν η πρώτη φορά που το Grok διακινούσε ασυναρτησίες, πατώντας σε αναρτήσεις χρηστών του Χ που αστειεύονταν στην πλατφόρμα. Στη διάρκεια της πρόσφατης έκλειψης ηλίου, λόγου χάρη, σύμφωνα με ρεπορτάζ του Gizmodo, το Grok ανάρτησε τίτλο που ανέφερε "Η Αλλόκοτη Συμπεριφορά του Ήλιου: Απορούν οι Ειδικοί". Παρότι είναι διασκεδαστικό να βλέπει κανείς τους χρήστες να σπάνε πλάκα με το Grok, η όλη κατάσταση φανερώνει ότι το Grok ενδέχεται να αποδειχτεί ευάλωτο στη χειραγώγηση από κακόβουλος παράγοντες, ώστε να προωθήσει σοβαρότερες πλαστές ή προπαγανδιστικές ειδήσεις. Οι δυνατότητες των μοντέλων τεχνητής νοημοσύνης παραμένουν εντυπωσιακές, όμως αυξάνεται η ανησυχία για την ποιότητα των δεδομένων με τα οποία εκπαιδεύονται και το περιστατικό με το Grok και τα "τούβλα" του Κλέι Τόμσον έρχεται να προστεθεί σε μια σειρά ανάλογων καταστάσεων όπου τα chatbots αναπαράγουν εντελώς λανθασμένα αποτελέσματα. Διαβάστε ολόκληρο το άρθρο
-

 Η Intel ισχυρίζεται ότι ο επιταχυντής «Gaudi 3» προσφέρει έως και 70% βελτιωμένη απόδοση στην εκπαίδευση μεγάλων γλωσσικών μοντέλων (LLMs) ή πολυτροπικών μοντέλων, 50% καλύτερη απόδοση στο συμπερασμό (inference) και 40% καλύτερη ενεργειακή αποδοτικότητα σε σχέση με τους επεξεργαστές/επιταχυντές NVIDIA H100. Ο νέος επιταχυντής AI παρουσιάστηκε με τη μορφή μίας dual-slot κάρτας PCIe Gen 5 (τύπου Universal Baseboard) με TDP 600W ή ως μονάδα OAM (Open Accelerator Module) με TDP ίσο με 900W. Η κάρτα PCIe Gen 5 έχει την ίδια μέγιστη απόδοση (1.835 TeraFLOPS σε FP8) με τη μονάδα OAM παρά το κατά 300 W χαμηλότερο TDP της. Η έκδοση PCIe Gen 5 λειτουργεί στο πλαίσιο μίας τετράδας από τέτοιες κάρτες ανά σύστημα, ενώ οι μονάδες OAM HL-325L μπορούν να λειτουργήσουν σε διαμόρφωση οκτώ επιταχυντών ανά διακομιστή. Κατασκευασμένος στον κόμβο N5 (5 nm) της TSMC, ο επιταχυντής AI της Intel ενσωματώνει 64x πυρήνες Tensor παρέχοντας διπλάσια απόδοση FP8 και τετραπλάσια απόδοση FP16 σε σχέση με την προηγούμενη γενιά του επιταχυντή, Gaudi 2. Ο επιταχυντής τεχνητής νοημοσύνης Gaudi 3 διαθέτει 128 GB μνήμης HBM2E με bandwidth που ισούται με 3,7 TB/s και 24x Ethernet NICs των 200 Gbps με δυνατότητες κλιμάκωσης σε διπλό NIC των 400 Gbps. Στη συσκευασία του, ο Gaudi 3 περιλαμβάνει 10x πλακίδια (tiles), τα οποία μπορείτε να διακρίνετε στην παραπάνω εικόνα. Μεταξύ των 2x κεντρικών πλακιδίων για το processing υπάρχουν 96 MB SRAM που λειτουργούν ως λανθάνουσα μνήμη χαμηλότερου επιπέδου (Low-Level Cache) που γεφυρώνει την επικοινωνία μεταξύ των πυρήνων Tensor και της μνήμης HBM2E. Σύμφωνα με την Intel, ο Gaudi 3 AI Accelerator υποστηρίζει clusters έως και 8.192x καρτών (1.024x nodes των οκτώ επιταχυντών έκαστο). Η μαζική παραγωγή του νέου Gaudi 3 αναμένεται να ξεκινήσει μέσα στο τρίτο τρίμηνο της χρονιάς. Στην ίδια εκδήλωση, η Intel ανακοίνωσε επίσης ότι θα υποστηρίξει τη νέα τυποποιημένη μορφή δεδομένων MXFP4 που αυξάνει τις επιδόσεις και έκανε γνωστό ότι βρίσκεται σε φάση ανάπτυξης ενός νέου AI NIC ASIC για δικτύωση που συμμορφώνεται με τα πρότυπα του Ultra Ethernet Consortium.
Η Intel ισχυρίζεται ότι ο επιταχυντής «Gaudi 3» προσφέρει έως και 70% βελτιωμένη απόδοση στην εκπαίδευση μεγάλων γλωσσικών μοντέλων (LLMs) ή πολυτροπικών μοντέλων, 50% καλύτερη απόδοση στο συμπερασμό (inference) και 40% καλύτερη ενεργειακή αποδοτικότητα σε σχέση με τους επεξεργαστές/επιταχυντές NVIDIA H100. Ο νέος επιταχυντής AI παρουσιάστηκε με τη μορφή μίας dual-slot κάρτας PCIe Gen 5 (τύπου Universal Baseboard) με TDP 600W ή ως μονάδα OAM (Open Accelerator Module) με TDP ίσο με 900W. Η κάρτα PCIe Gen 5 έχει την ίδια μέγιστη απόδοση (1.835 TeraFLOPS σε FP8) με τη μονάδα OAM παρά το κατά 300 W χαμηλότερο TDP της. Η έκδοση PCIe Gen 5 λειτουργεί στο πλαίσιο μίας τετράδας από τέτοιες κάρτες ανά σύστημα, ενώ οι μονάδες OAM HL-325L μπορούν να λειτουργήσουν σε διαμόρφωση οκτώ επιταχυντών ανά διακομιστή. Κατασκευασμένος στον κόμβο N5 (5 nm) της TSMC, ο επιταχυντής AI της Intel ενσωματώνει 64x πυρήνες Tensor παρέχοντας διπλάσια απόδοση FP8 και τετραπλάσια απόδοση FP16 σε σχέση με την προηγούμενη γενιά του επιταχυντή, Gaudi 2. Ο επιταχυντής τεχνητής νοημοσύνης Gaudi 3 διαθέτει 128 GB μνήμης HBM2E με bandwidth που ισούται με 3,7 TB/s και 24x Ethernet NICs των 200 Gbps με δυνατότητες κλιμάκωσης σε διπλό NIC των 400 Gbps. Στη συσκευασία του, ο Gaudi 3 περιλαμβάνει 10x πλακίδια (tiles), τα οποία μπορείτε να διακρίνετε στην παραπάνω εικόνα. Μεταξύ των 2x κεντρικών πλακιδίων για το processing υπάρχουν 96 MB SRAM που λειτουργούν ως λανθάνουσα μνήμη χαμηλότερου επιπέδου (Low-Level Cache) που γεφυρώνει την επικοινωνία μεταξύ των πυρήνων Tensor και της μνήμης HBM2E. Σύμφωνα με την Intel, ο Gaudi 3 AI Accelerator υποστηρίζει clusters έως και 8.192x καρτών (1.024x nodes των οκτώ επιταχυντών έκαστο). Η μαζική παραγωγή του νέου Gaudi 3 αναμένεται να ξεκινήσει μέσα στο τρίτο τρίμηνο της χρονιάς. Στην ίδια εκδήλωση, η Intel ανακοίνωσε επίσης ότι θα υποστηρίξει τη νέα τυποποιημένη μορφή δεδομένων MXFP4 που αυξάνει τις επιδόσεις και έκανε γνωστό ότι βρίσκεται σε φάση ανάπτυξης ενός νέου AI NIC ASIC για δικτύωση που συμμορφώνεται με τα πρότυπα του Ultra Ethernet Consortium. -
Κατά τη διάρκεια της εκδήλωσης Vision 2024, η Intel ανακοίνωσε τον πλέον σύγχρονο επιταχυντή Τεχνητής Νοημοσύνης «Gaudi 3» υποσχόμενος σημαντικές βελτιώσεις σε σχέση με τον προκάτοχό του. Η Intel ισχυρίζεται ότι ο επιταχυντής «Gaudi 3» προσφέρει έως και 70% βελτιωμένη απόδοση στην εκπαίδευση μεγάλων γλωσσικών μοντέλων (LLMs) ή πολυτροπικών μοντέλων, 50% καλύτερη απόδοση στο συμπερασμό (inference) και 40% καλύτερη ενεργειακή αποδοτικότητα σε σχέση με τους επεξεργαστές/επιταχυντές NVIDIA H100. Ο νέος επιταχυντής AI παρουσιάστηκε με τη μορφή μίας dual-slot κάρτας PCIe Gen 5 (τύπου Universal Baseboard) με TDP 600W ή ως μονάδα OAM (Open Accelerator Module) με TDP ίσο με 900W. Η κάρτα PCIe Gen 5 έχει την ίδια μέγιστη απόδοση (1.835 TeraFLOPS σε FP8) με τη μονάδα OAM παρά το κατά 300 W χαμηλότερο TDP της. Η έκδοση PCIe Gen 5 λειτουργεί στο πλαίσιο μίας τετράδας από τέτοιες κάρτες ανά σύστημα, ενώ οι μονάδες OAM HL-325L μπορούν να λειτουργήσουν σε διαμόρφωση οκτώ επιταχυντών ανά διακομιστή. Κατασκευασμένος στον κόμβο N5 (5 nm) της TSMC, ο επιταχυντής AI της Intel ενσωματώνει 64x πυρήνες Tensor παρέχοντας διπλάσια απόδοση FP8 και τετραπλάσια απόδοση FP16 σε σχέση με την προηγούμενη γενιά του επιταχυντή, Gaudi 2. Ο επιταχυντής τεχνητής νοημοσύνης Gaudi 3 διαθέτει 128 GB μνήμης HBM2E με bandwidth που ισούται με 3,7 TB/s και 24x Ethernet NICs των 200 Gbps με δυνατότητες κλιμάκωσης σε διπλό NIC των 400 Gbps. Στη συσκευασία του, ο Gaudi 3 περιλαμβάνει 10x πλακίδια (tiles), τα οποία μπορείτε να διακρίνετε στην παραπάνω εικόνα. Μεταξύ των 2x κεντρικών πλακιδίων για το processing υπάρχουν 96 MB SRAM που λειτουργούν ως λανθάνουσα μνήμη χαμηλότερου επιπέδου (Low-Level Cache) που γεφυρώνει την επικοινωνία μεταξύ των πυρήνων Tensor και της μνήμης HBM2E. Σύμφωνα με την Intel, ο Gaudi 3 AI Accelerator υποστηρίζει clusters έως και 8.192x καρτών (1.024x nodes των οκτώ επιταχυντών έκαστο). Η μαζική παραγωγή του νέου Gaudi 3 αναμένεται να ξεκινήσει μέσα στο τρίτο τρίμηνο της χρονιάς. Στην ίδια εκδήλωση, η Intel ανακοίνωσε επίσης ότι θα υποστηρίξει τη νέα τυποποιημένη μορφή δεδομένων MXFP4 που αυξάνει τις επιδόσεις και έκανε γνωστό ότι βρίσκεται σε φάση ανάπτυξης ενός νέου AI NIC ASIC για δικτύωση που συμμορφώνεται με τα πρότυπα του Ultra Ethernet Consortium. Διαβάστε ολόκληρο το άρθρο
-
 Στόχος είναι να διατηρήσει το συγκριτικό πλεονέκτημα που διαθέτει στην παραγωγή ημιαγωγών. Ο πρόεδρος της Νότιας Κορέας, Γιουν Σουκ Γιολ, ανακοίνωσε ότι η χώρα του προτίθεται να επενδύσει κεφάλαια τα οποία αγγίζουν τα 7 δισεκατομμύρια δολάρια στον τομέα της τεχνητής νοημοσύνης ως το 2027, στο πλαίσιο των προσπαθειών που καταβάλει η ασιατική χώρα να διατηρήσει ηγετικό ρόλο στην παραγωγή ημιαγωγών αιχμής. Η ανακοίνωση, η οποία περιλαμβάνει επιπλέον ποσό ενός δισεκατομμυρίου δολαρίων για την ενίσχυση των εταιριών παραγωγής ημιαγωγών για χρήση στην τεχνητή νοημοσύνη, έρχεται σε μια στιγμή κατά την οποία η Νότια Κορέα επιχειρεί να ακολουθήσει τους ρυθμούς χωρών όπως οι Ηνωμένες Πολιτείες, η Κίνα και η Ιαπωνία, που επίσης στηρίζουν δυναμικά την ενίσχυση των εφοδιαστικών αλυσίδων στον τομέα των ημιαγωγών, μέσα στην επικράτειά τους. Οι ημιαγωγοί αποτελούν βασικό θεμέλιο της εξωστρεφούς, εξαγωγικής οικονομίας της Νότιας Κορέας. Το Μάρτιο, οι εξαγωγές αυτές έφτασαν στα υψηλότερα επίπεδα των τελευταίων 21 μηνών, αντιστοιχώντας σε πωλήσεις 11,7 δισεκατομμυρίων δολαρίων ή αλλιώς το ένα πέμπτο των συνολικών εξαγωγών που επιτυγχάνει η τέταρτη μεγαλύτερη οικονομία της Ασίας. "Ο τρέχων ανταγωνισμός στους ημιαγωγούς συνιστά βιομηχανικό πόλεμο μεταξύ των εθνών", δήλωσε ο Γιουν, απευθυνόμενος σε πολιτικά και βιομηχανικά στελέχη, την περασμένη εβδομάδα. Μέσα από τον προϋπολογισμό αυτών των επενδύσεων και του αντίστοιχου επενδυτικού ταμείου, η Νότια Κορέα σχεδιάζει να επεκτείνει σημαντικά την έρευνα και την ανάπτυξη ημιαγωγών που χρησιμοποιούνται στην τεχνητή νοημοσύνη, όπως τεχνητές νευρωνικές επεξεργαστικές μονάδες (NPU) καθώς και μνήμες επόμενης γενιάς, όπως ανέφερε η κυβέρνηση της χώρας. Οι νοτιοκορεατικές αρχές σκοπεύουν επίσης να προωθήσουν την ανάπτυξη επόμενης γενιάς μοντέλων γενικής τεχνητής νοημοσύνης (AGI) αλλά και τεχνολογίες ασφαλείας, που υπερβαίνουν τα υφιστάμενα μοντέλα. Ο στόχος που έθεσε ο Γιουν είναι να καταλάβει η Νότια Κορέα θέση μεταξύ των τριών κορυφαίων χωρών στον τομέα της τεχνητής νοημοσύνης και να εξασφαλίσει μερίδιο της τάξης του 10% ή και περισσότερο στη διεθνή αγορά ημιαγωγών, έως το 2030. Παράλληλα, ο Νοτιοκορεάτης πρόεδρος επισήμανε πως ο αντίκτυπος του πρόσφατου ισχυρού σεισμού στην Ταϊβάν, η οποία κατέχει ηγετική θέση στην αγορά ημιαγωγών, είναι περιορισμένος σε ό,τι αφορά τις εταιρίες της Νότιας Κορέας μέχρι στιγμής, όμως ζήτησε να υπάρξει διεξοδική προετοιμασία, για το ενδεχόμενο να καταγραφούν αβεβαιότητες ως προς το μελλοντικό εφοδιασμό της αγοράς. Διαβάστε ολόκληρο το άρθρο
Στόχος είναι να διατηρήσει το συγκριτικό πλεονέκτημα που διαθέτει στην παραγωγή ημιαγωγών. Ο πρόεδρος της Νότιας Κορέας, Γιουν Σουκ Γιολ, ανακοίνωσε ότι η χώρα του προτίθεται να επενδύσει κεφάλαια τα οποία αγγίζουν τα 7 δισεκατομμύρια δολάρια στον τομέα της τεχνητής νοημοσύνης ως το 2027, στο πλαίσιο των προσπαθειών που καταβάλει η ασιατική χώρα να διατηρήσει ηγετικό ρόλο στην παραγωγή ημιαγωγών αιχμής. Η ανακοίνωση, η οποία περιλαμβάνει επιπλέον ποσό ενός δισεκατομμυρίου δολαρίων για την ενίσχυση των εταιριών παραγωγής ημιαγωγών για χρήση στην τεχνητή νοημοσύνη, έρχεται σε μια στιγμή κατά την οποία η Νότια Κορέα επιχειρεί να ακολουθήσει τους ρυθμούς χωρών όπως οι Ηνωμένες Πολιτείες, η Κίνα και η Ιαπωνία, που επίσης στηρίζουν δυναμικά την ενίσχυση των εφοδιαστικών αλυσίδων στον τομέα των ημιαγωγών, μέσα στην επικράτειά τους. Οι ημιαγωγοί αποτελούν βασικό θεμέλιο της εξωστρεφούς, εξαγωγικής οικονομίας της Νότιας Κορέας. Το Μάρτιο, οι εξαγωγές αυτές έφτασαν στα υψηλότερα επίπεδα των τελευταίων 21 μηνών, αντιστοιχώντας σε πωλήσεις 11,7 δισεκατομμυρίων δολαρίων ή αλλιώς το ένα πέμπτο των συνολικών εξαγωγών που επιτυγχάνει η τέταρτη μεγαλύτερη οικονομία της Ασίας. "Ο τρέχων ανταγωνισμός στους ημιαγωγούς συνιστά βιομηχανικό πόλεμο μεταξύ των εθνών", δήλωσε ο Γιουν, απευθυνόμενος σε πολιτικά και βιομηχανικά στελέχη, την περασμένη εβδομάδα. Μέσα από τον προϋπολογισμό αυτών των επενδύσεων και του αντίστοιχου επενδυτικού ταμείου, η Νότια Κορέα σχεδιάζει να επεκτείνει σημαντικά την έρευνα και την ανάπτυξη ημιαγωγών που χρησιμοποιούνται στην τεχνητή νοημοσύνη, όπως τεχνητές νευρωνικές επεξεργαστικές μονάδες (NPU) καθώς και μνήμες επόμενης γενιάς, όπως ανέφερε η κυβέρνηση της χώρας. Οι νοτιοκορεατικές αρχές σκοπεύουν επίσης να προωθήσουν την ανάπτυξη επόμενης γενιάς μοντέλων γενικής τεχνητής νοημοσύνης (AGI) αλλά και τεχνολογίες ασφαλείας, που υπερβαίνουν τα υφιστάμενα μοντέλα. Ο στόχος που έθεσε ο Γιουν είναι να καταλάβει η Νότια Κορέα θέση μεταξύ των τριών κορυφαίων χωρών στον τομέα της τεχνητής νοημοσύνης και να εξασφαλίσει μερίδιο της τάξης του 10% ή και περισσότερο στη διεθνή αγορά ημιαγωγών, έως το 2030. Παράλληλα, ο Νοτιοκορεάτης πρόεδρος επισήμανε πως ο αντίκτυπος του πρόσφατου ισχυρού σεισμού στην Ταϊβάν, η οποία κατέχει ηγετική θέση στην αγορά ημιαγωγών, είναι περιορισμένος σε ό,τι αφορά τις εταιρίες της Νότιας Κορέας μέχρι στιγμής, όμως ζήτησε να υπάρξει διεξοδική προετοιμασία, για το ενδεχόμενο να καταγραφούν αβεβαιότητες ως προς το μελλοντικό εφοδιασμό της αγοράς. Διαβάστε ολόκληρο το άρθρο -
 Οι χρήστες θα μπορούν να ζητούν από την τεχνητή νοημοσύνη προτάσεις τραγουδιών, μέσα από οδηγίες όπως "Κάνε με να νοιώσω σαν κυνηγός βρικολάκων από την ταινία Blade"... Μετά τους πειραματισμούς με τη δημιουργία λιστών μέσω τεχνητής νοημοσύνης, με τη λειτουργία DJ πέρυσι, η Spotify διαθέτει σε beta ένα νέο εργαλείο που επιτρέπει στους χρήστες να δημιουργούν λίστες βασισμένες σε γραπτές περιγραφές. Η νέα AI Playlist beta σε πρώτο στάδιο διατίθεται στους συνδρομητές του Spotify Premium σε συσκευές στο Ηνωμένο Βασίλειο και την Αυστραλία. Οι χρήστες συσκευών Android και iOS σε αυτές τις χώρες μπορούν να βρουν τη νέα λειτουργία πηγαίνοντας στην επιλογή "Your Library" και πατώντας εκεί το "+" στην επάνω δεξιά γωνία της σελίδας. Έπειτα, επιλέγουν τη λειτουργία AI Playlist από το μενού που εμφανίζεται και μπορούν να πληκτρολογήσουν τις οδηγίες τους, για παράδειγμα "μουσική για διάβασμα μια κρύα, βροχερή μέρα", ώστε να προκύψει μια λίστα 30 τραγουδιών που ταιριάζουν με αυτή τη διάθεση. Τα αποτελέσματα μπορούν να προσαρμοστούν, μέσα από επιπλέον οδηγίες, όπως "πιο λυπητερή μουσική", ώσπου ο χρήστης να ικανοποιηθεί από το αποτέλεσμα, οπότε η λίστα μπορεί να αποθηκευτεί, πατώντας στην επιλογή "create", επάνω δεξιά. Οι πρώτες δοκιμές οδήγησαν σε εντυπωσιακά αποτελέσματα, ακόμη και όταν οι οδηγίες ήταν πολύ περιορισμένου φάσματος. Για παράδειγμα, προέκυψε μια θαυμάσια συλλογή από δυναμική, techno μουσική όταν η AI Playlist κλήθηκε να δημιουργήσει μια λίστα τραγουδιών η οποία θα "με κάνει να νοιώσω σαν κυνηγός βρικολάκων από το Blade (1998)" ενώ συνοδεύτηκε και από τον τίτλο "Η Ουσία του Blade", χωρίς να χρειαστεί επιπλέον οδηγία. Η Spotify αναφέρει πως οι χρήστες θα έχουν καλύτερα αποτελέσματα χρησιμοποιώντας οδηγίες που περιέχουν συνδυασμό ειδών μουσικής, διαθέσεων, καλλιτεχνών ή δεκαετιών και ότι μπορούν να χρησιμοποιηθούν αναφορές σε τόπους, ζώα, δραστηριότητες, χαρακτήρες ταινιών, χρώματα, ακόμη και emoji. Η εταιρία αναφέρει πως θα συνεχίσει να βελτιώνει αυτή τη λειτουργία, στην πορεία των επόμενων μηνών. Υπάρχουν, βέβαια, ορισμένοι περιορισμοί που θα πρέπει να έχουν υπόψη τους οι χρήστες: η AI Playlist δεν μπορεί να εμφανίσει αποτελέσματα ακολουθώντας μη μουσικές οδηγίες, όπως για παράδειγμα αναφορές σε τρέχουσες ειδήσεις, ενώ στο μοντέλο εφαρμόζονται μέτρα προκειμένου να ακυρώνονται οδηγίες οι οποίες είναι προσβλητικές. Η AI Playlist είναι ένας πολύ ταχύτερος τρόπος ώστε να δημιουργηθεί μια λίστα, από ό,τι να επιλέξει κανείς ένα προς ένα τα τραγούδια, ενώ μπορεί να λειτουργήσει και ως εργαλείο ανακάλυψης άλλων μουσικών προτάσεων, για εκείνους που θα ήθελαν να ακούσουν νέα κομμάτια τα οποία ακολουθούν μια συγκεκριμένη αισθητική. Ήδη, δηλαδή, η AI Playlist δείχνει πολύ πιο χρήσιμη από ότι ο AI DJ της Spotify, που δημιουργεί μια λίστα βασισμένη στο τι έχει ακούσει προηγουμένως ο χρήστης, με περιορισμένες επιλογές για την τροποποίηση της τελικής πρότασης. Η νέα λειτουργία, πάντως, θα μπορούσε να ήταν ένας από τους παράγοντες που συνέβαλαν στις αυξήσεις τιμών τις οποίες αναμένεται να ανακοινώσει η Spotify αργότερα μέσα στο χρόνο. Μέχρι στιγμής, πάντως, η εταιρία δεν έχει ανακοινώσει πότε προτίθεται να καταστήσει την AI Playlist διαθέσιμη και σε άλλες περιοχές. Διαβάστε ολόκληρο το άρθρο
Οι χρήστες θα μπορούν να ζητούν από την τεχνητή νοημοσύνη προτάσεις τραγουδιών, μέσα από οδηγίες όπως "Κάνε με να νοιώσω σαν κυνηγός βρικολάκων από την ταινία Blade"... Μετά τους πειραματισμούς με τη δημιουργία λιστών μέσω τεχνητής νοημοσύνης, με τη λειτουργία DJ πέρυσι, η Spotify διαθέτει σε beta ένα νέο εργαλείο που επιτρέπει στους χρήστες να δημιουργούν λίστες βασισμένες σε γραπτές περιγραφές. Η νέα AI Playlist beta σε πρώτο στάδιο διατίθεται στους συνδρομητές του Spotify Premium σε συσκευές στο Ηνωμένο Βασίλειο και την Αυστραλία. Οι χρήστες συσκευών Android και iOS σε αυτές τις χώρες μπορούν να βρουν τη νέα λειτουργία πηγαίνοντας στην επιλογή "Your Library" και πατώντας εκεί το "+" στην επάνω δεξιά γωνία της σελίδας. Έπειτα, επιλέγουν τη λειτουργία AI Playlist από το μενού που εμφανίζεται και μπορούν να πληκτρολογήσουν τις οδηγίες τους, για παράδειγμα "μουσική για διάβασμα μια κρύα, βροχερή μέρα", ώστε να προκύψει μια λίστα 30 τραγουδιών που ταιριάζουν με αυτή τη διάθεση. Τα αποτελέσματα μπορούν να προσαρμοστούν, μέσα από επιπλέον οδηγίες, όπως "πιο λυπητερή μουσική", ώσπου ο χρήστης να ικανοποιηθεί από το αποτέλεσμα, οπότε η λίστα μπορεί να αποθηκευτεί, πατώντας στην επιλογή "create", επάνω δεξιά. Οι πρώτες δοκιμές οδήγησαν σε εντυπωσιακά αποτελέσματα, ακόμη και όταν οι οδηγίες ήταν πολύ περιορισμένου φάσματος. Για παράδειγμα, προέκυψε μια θαυμάσια συλλογή από δυναμική, techno μουσική όταν η AI Playlist κλήθηκε να δημιουργήσει μια λίστα τραγουδιών η οποία θα "με κάνει να νοιώσω σαν κυνηγός βρικολάκων από το Blade (1998)" ενώ συνοδεύτηκε και από τον τίτλο "Η Ουσία του Blade", χωρίς να χρειαστεί επιπλέον οδηγία. Η Spotify αναφέρει πως οι χρήστες θα έχουν καλύτερα αποτελέσματα χρησιμοποιώντας οδηγίες που περιέχουν συνδυασμό ειδών μουσικής, διαθέσεων, καλλιτεχνών ή δεκαετιών και ότι μπορούν να χρησιμοποιηθούν αναφορές σε τόπους, ζώα, δραστηριότητες, χαρακτήρες ταινιών, χρώματα, ακόμη και emoji. Η εταιρία αναφέρει πως θα συνεχίσει να βελτιώνει αυτή τη λειτουργία, στην πορεία των επόμενων μηνών. Υπάρχουν, βέβαια, ορισμένοι περιορισμοί που θα πρέπει να έχουν υπόψη τους οι χρήστες: η AI Playlist δεν μπορεί να εμφανίσει αποτελέσματα ακολουθώντας μη μουσικές οδηγίες, όπως για παράδειγμα αναφορές σε τρέχουσες ειδήσεις, ενώ στο μοντέλο εφαρμόζονται μέτρα προκειμένου να ακυρώνονται οδηγίες οι οποίες είναι προσβλητικές. Η AI Playlist είναι ένας πολύ ταχύτερος τρόπος ώστε να δημιουργηθεί μια λίστα, από ό,τι να επιλέξει κανείς ένα προς ένα τα τραγούδια, ενώ μπορεί να λειτουργήσει και ως εργαλείο ανακάλυψης άλλων μουσικών προτάσεων, για εκείνους που θα ήθελαν να ακούσουν νέα κομμάτια τα οποία ακολουθούν μια συγκεκριμένη αισθητική. Ήδη, δηλαδή, η AI Playlist δείχνει πολύ πιο χρήσιμη από ότι ο AI DJ της Spotify, που δημιουργεί μια λίστα βασισμένη στο τι έχει ακούσει προηγουμένως ο χρήστης, με περιορισμένες επιλογές για την τροποποίηση της τελικής πρότασης. Η νέα λειτουργία, πάντως, θα μπορούσε να ήταν ένας από τους παράγοντες που συνέβαλαν στις αυξήσεις τιμών τις οποίες αναμένεται να ανακοινώσει η Spotify αργότερα μέσα στο χρόνο. Μέχρι στιγμής, πάντως, η εταιρία δεν έχει ανακοινώσει πότε προτίθεται να καταστήσει την AI Playlist διαθέσιμη και σε άλλες περιοχές. Διαβάστε ολόκληρο το άρθρο -
 Ο πρόεδρος της Νότιας Κορέας, Γιουν Σουκ Γιολ, ανακοίνωσε ότι η χώρα του προτίθεται να επενδύσει κεφάλαια τα οποία αγγίζουν τα 7 δισεκατομμύρια δολάρια στον τομέα της τεχνητής νοημοσύνης ως το 2027, στο πλαίσιο των προσπαθειών που καταβάλει η ασιατική χώρα να διατηρήσει ηγετικό ρόλο στην παραγωγή ημιαγωγών αιχμής. Η ανακοίνωση, η οποία περιλαμβάνει επιπλέον ποσό ενός δισεκατομμυρίου δολαρίων για την ενίσχυση των εταιριών παραγωγής ημιαγωγών για χρήση στην τεχνητή νοημοσύνη, έρχεται σε μια στιγμή κατά την οποία η Νότια Κορέα επιχειρεί να ακολουθήσει τους ρυθμούς χωρών όπως οι Ηνωμένες Πολιτείες, η Κίνα και η Ιαπωνία, που επίσης στηρίζουν δυναμικά την ενίσχυση των εφοδιαστικών αλυσίδων στον τομέα των ημιαγωγών, μέσα στην επικράτειά τους. Οι ημιαγωγοί αποτελούν βασικό θεμέλιο της εξωστρεφούς, εξαγωγικής οικονομίας της Νότιας Κορέας. Το Μάρτιο, οι εξαγωγές αυτές έφτασαν στα υψηλότερα επίπεδα των τελευταίων 21 μηνών, αντιστοιχώντας σε πωλήσεις 11,7 δισεκατομμυρίων δολαρίων ή αλλιώς το ένα πέμπτο των συνολικών εξαγωγών που επιτυγχάνει η τέταρτη μεγαλύτερη οικονομία της Ασίας. "Ο τρέχων ανταγωνισμός στους ημιαγωγούς συνιστά βιομηχανικό πόλεμο μεταξύ των εθνών", δήλωσε ο Γιουν, απευθυνόμενος σε πολιτικά και βιομηχανικά στελέχη, την περασμένη εβδομάδα. Μέσα από τον προϋπολογισμό αυτών των επενδύσεων και του αντίστοιχου επενδυτικού ταμείου, η Νότια Κορέα σχεδιάζει να επεκτείνει σημαντικά την έρευνα και την ανάπτυξη ημιαγωγών που χρησιμοποιούνται στην τεχνητή νοημοσύνη, όπως τεχνητές νευρωνικές επεξεργαστικές μονάδες (NPU) καθώς και μνήμες επόμενης γενιάς, όπως ανέφερε η κυβέρνηση της χώρας. Οι νοτιοκορεατικές αρχές σκοπεύουν επίσης να προωθήσουν την ανάπτυξη επόμενης γενιάς μοντέλων γενικής τεχνητής νοημοσύνης (AGI) αλλά και τεχνολογίες ασφαλείας, που υπερβαίνουν τα υφιστάμενα μοντέλα. Ο στόχος που έθεσε ο Γιουν είναι να καταλάβει η Νότια Κορέα θέση μεταξύ των τριών κορυφαίων χωρών στον τομέα της τεχνητής νοημοσύνης και να εξασφαλίσει μερίδιο της τάξης του 10% ή και περισσότερο στη διεθνή αγορά ημιαγωγών, έως το 2030. Παράλληλα, ο Νοτιοκορεάτης πρόεδρος επισήμανε πως ο αντίκτυπος του πρόσφατου ισχυρού σεισμού στην Ταϊβάν, η οποία κατέχει ηγετική θέση στην αγορά ημιαγωγών, είναι περιορισμένος σε ό,τι αφορά τις εταιρίες της Νότιας Κορέας μέχρι στιγμής, όμως ζήτησε να υπάρξει διεξοδική προετοιμασία, για το ενδεχόμενο να καταγραφούν αβεβαιότητες ως προς το μελλοντικό εφοδιασμό της αγοράς.
Ο πρόεδρος της Νότιας Κορέας, Γιουν Σουκ Γιολ, ανακοίνωσε ότι η χώρα του προτίθεται να επενδύσει κεφάλαια τα οποία αγγίζουν τα 7 δισεκατομμύρια δολάρια στον τομέα της τεχνητής νοημοσύνης ως το 2027, στο πλαίσιο των προσπαθειών που καταβάλει η ασιατική χώρα να διατηρήσει ηγετικό ρόλο στην παραγωγή ημιαγωγών αιχμής. Η ανακοίνωση, η οποία περιλαμβάνει επιπλέον ποσό ενός δισεκατομμυρίου δολαρίων για την ενίσχυση των εταιριών παραγωγής ημιαγωγών για χρήση στην τεχνητή νοημοσύνη, έρχεται σε μια στιγμή κατά την οποία η Νότια Κορέα επιχειρεί να ακολουθήσει τους ρυθμούς χωρών όπως οι Ηνωμένες Πολιτείες, η Κίνα και η Ιαπωνία, που επίσης στηρίζουν δυναμικά την ενίσχυση των εφοδιαστικών αλυσίδων στον τομέα των ημιαγωγών, μέσα στην επικράτειά τους. Οι ημιαγωγοί αποτελούν βασικό θεμέλιο της εξωστρεφούς, εξαγωγικής οικονομίας της Νότιας Κορέας. Το Μάρτιο, οι εξαγωγές αυτές έφτασαν στα υψηλότερα επίπεδα των τελευταίων 21 μηνών, αντιστοιχώντας σε πωλήσεις 11,7 δισεκατομμυρίων δολαρίων ή αλλιώς το ένα πέμπτο των συνολικών εξαγωγών που επιτυγχάνει η τέταρτη μεγαλύτερη οικονομία της Ασίας. "Ο τρέχων ανταγωνισμός στους ημιαγωγούς συνιστά βιομηχανικό πόλεμο μεταξύ των εθνών", δήλωσε ο Γιουν, απευθυνόμενος σε πολιτικά και βιομηχανικά στελέχη, την περασμένη εβδομάδα. Μέσα από τον προϋπολογισμό αυτών των επενδύσεων και του αντίστοιχου επενδυτικού ταμείου, η Νότια Κορέα σχεδιάζει να επεκτείνει σημαντικά την έρευνα και την ανάπτυξη ημιαγωγών που χρησιμοποιούνται στην τεχνητή νοημοσύνη, όπως τεχνητές νευρωνικές επεξεργαστικές μονάδες (NPU) καθώς και μνήμες επόμενης γενιάς, όπως ανέφερε η κυβέρνηση της χώρας. Οι νοτιοκορεατικές αρχές σκοπεύουν επίσης να προωθήσουν την ανάπτυξη επόμενης γενιάς μοντέλων γενικής τεχνητής νοημοσύνης (AGI) αλλά και τεχνολογίες ασφαλείας, που υπερβαίνουν τα υφιστάμενα μοντέλα. Ο στόχος που έθεσε ο Γιουν είναι να καταλάβει η Νότια Κορέα θέση μεταξύ των τριών κορυφαίων χωρών στον τομέα της τεχνητής νοημοσύνης και να εξασφαλίσει μερίδιο της τάξης του 10% ή και περισσότερο στη διεθνή αγορά ημιαγωγών, έως το 2030. Παράλληλα, ο Νοτιοκορεάτης πρόεδρος επισήμανε πως ο αντίκτυπος του πρόσφατου ισχυρού σεισμού στην Ταϊβάν, η οποία κατέχει ηγετική θέση στην αγορά ημιαγωγών, είναι περιορισμένος σε ό,τι αφορά τις εταιρίες της Νότιας Κορέας μέχρι στιγμής, όμως ζήτησε να υπάρξει διεξοδική προετοιμασία, για το ενδεχόμενο να καταγραφούν αβεβαιότητες ως προς το μελλοντικό εφοδιασμό της αγοράς. -
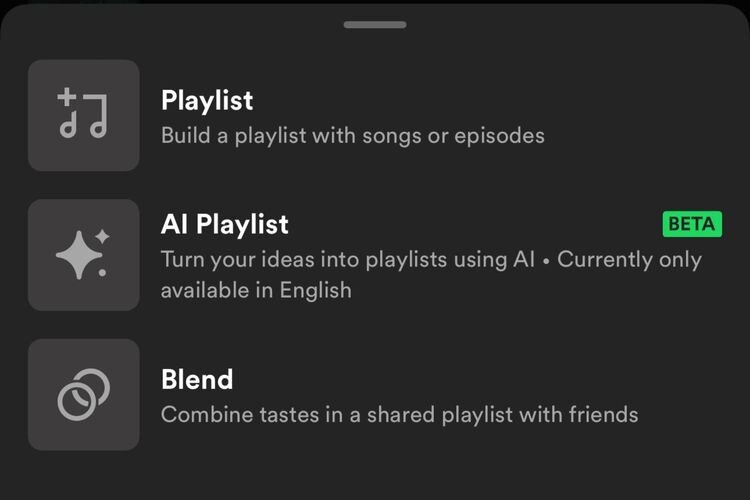 Μετά τους πειραματισμούς με τη δημιουργία λιστών μέσω τεχνητής νοημοσύνης, με τη λειτουργία DJ πέρυσι, η Spotify διαθέτει σε beta ένα νέο εργαλείο που επιτρέπει στους χρήστες να δημιουργούν λίστες βασισμένες σε γραπτές περιγραφές. Η νέα AI Playlist beta σε πρώτο στάδιο διατίθεται στους συνδρομητές του Spotify Premium σε συσκευές στο Ηνωμένο Βασίλειο και την Αυστραλία. Οι χρήστες συσκευών Android και iOS σε αυτές τις χώρες μπορούν να βρουν τη νέα λειτουργία πηγαίνοντας στην επιλογή "Your Library" και πατώντας εκεί το "+" στην επάνω δεξιά γωνία της σελίδας. Έπειτα, επιλέγουν τη λειτουργία AI Playlist από το μενού που εμφανίζεται και μπορούν να πληκτρολογήσουν τις οδηγίες τους, για παράδειγμα "μουσική για διάβασμα μια κρύα, βροχερή μέρα", ώστε να προκύψει μια λίστα 30 τραγουδιών που ταιριάζουν με αυτή τη διάθεση. Τα αποτελέσματα μπορούν να προσαρμοστούν, μέσα από επιπλέον οδηγίες, όπως "πιο λυπητερή μουσική", ώσπου ο χρήστης να ικανοποιηθεί από το αποτέλεσμα, οπότε η λίστα μπορεί να αποθηκευτεί, πατώντας στην επιλογή "create", επάνω δεξιά. Οι πρώτες δοκιμές οδήγησαν σε εντυπωσιακά αποτελέσματα, ακόμη και όταν οι οδηγίες ήταν πολύ περιορισμένου φάσματος. Για παράδειγμα, προέκυψε μια θαυμάσια συλλογή από δυναμική, techno μουσική όταν η AI Playlist κλήθηκε να δημιουργήσει μια λίστα τραγουδιών η οποία θα "με κάνει να νοιώσω σαν κυνηγός βρικολάκων από το Blade (1998)" ενώ συνοδεύτηκε και από τον τίτλο "Η Ουσία του Blade", χωρίς να χρειαστεί επιπλέον οδηγία. Η Spotify αναφέρει πως οι χρήστες θα έχουν καλύτερα αποτελέσματα χρησιμοποιώντας οδηγίες που περιέχουν συνδυασμό ειδών μουσικής, διαθέσεων, καλλιτεχνών ή δεκαετιών και ότι μπορούν να χρησιμοποιηθούν αναφορές σε τόπους, ζώα, δραστηριότητες, χαρακτήρες ταινιών, χρώματα, ακόμη και emoji. Η εταιρία αναφέρει πως θα συνεχίσει να βελτιώνει αυτή τη λειτουργία, στην πορεία των επόμενων μηνών. Υπάρχουν, βέβαια, ορισμένοι περιορισμοί που θα πρέπει να έχουν υπόψη τους οι χρήστες: η AI Playlist δεν μπορεί να εμφανίσει αποτελέσματα ακολουθώντας μη μουσικές οδηγίες, όπως για παράδειγμα αναφορές σε τρέχουσες ειδήσεις, ενώ στο μοντέλο εφαρμόζονται μέτρα προκειμένου να ακυρώνονται οδηγίες οι οποίες είναι προσβλητικές. Η AI Playlist είναι ένας πολύ ταχύτερος τρόπος ώστε να δημιουργηθεί μια λίστα, από ό,τι να επιλέξει κανείς ένα προς ένα τα τραγούδια, ενώ μπορεί να λειτουργήσει και ως εργαλείο ανακάλυψης άλλων μουσικών προτάσεων, για εκείνους που θα ήθελαν να ακούσουν νέα κομμάτια τα οποία ακολουθούν μια συγκεκριμένη αισθητική. Ήδη, δηλαδή, η AI Playlist δείχνει πολύ πιο χρήσιμη από ότι ο AI DJ της Spotify, που δημιουργεί μια λίστα βασισμένη στο τι έχει ακούσει προηγουμένως ο χρήστης, με περιορισμένες επιλογές για την τροποποίηση της τελικής πρότασης. Η νέα λειτουργία, πάντως, θα μπορούσε να ήταν ένας από τους παράγοντες που συνέβαλαν στις αυξήσεις τιμών τις οποίες αναμένεται να ανακοινώσει η Spotify αργότερα μέσα στο χρόνο. Μέχρι στιγμής, πάντως, η εταιρία δεν έχει ανακοινώσει πότε προτίθεται να καταστήσει την AI Playlist διαθέσιμη και σε άλλες περιοχές.
Μετά τους πειραματισμούς με τη δημιουργία λιστών μέσω τεχνητής νοημοσύνης, με τη λειτουργία DJ πέρυσι, η Spotify διαθέτει σε beta ένα νέο εργαλείο που επιτρέπει στους χρήστες να δημιουργούν λίστες βασισμένες σε γραπτές περιγραφές. Η νέα AI Playlist beta σε πρώτο στάδιο διατίθεται στους συνδρομητές του Spotify Premium σε συσκευές στο Ηνωμένο Βασίλειο και την Αυστραλία. Οι χρήστες συσκευών Android και iOS σε αυτές τις χώρες μπορούν να βρουν τη νέα λειτουργία πηγαίνοντας στην επιλογή "Your Library" και πατώντας εκεί το "+" στην επάνω δεξιά γωνία της σελίδας. Έπειτα, επιλέγουν τη λειτουργία AI Playlist από το μενού που εμφανίζεται και μπορούν να πληκτρολογήσουν τις οδηγίες τους, για παράδειγμα "μουσική για διάβασμα μια κρύα, βροχερή μέρα", ώστε να προκύψει μια λίστα 30 τραγουδιών που ταιριάζουν με αυτή τη διάθεση. Τα αποτελέσματα μπορούν να προσαρμοστούν, μέσα από επιπλέον οδηγίες, όπως "πιο λυπητερή μουσική", ώσπου ο χρήστης να ικανοποιηθεί από το αποτέλεσμα, οπότε η λίστα μπορεί να αποθηκευτεί, πατώντας στην επιλογή "create", επάνω δεξιά. Οι πρώτες δοκιμές οδήγησαν σε εντυπωσιακά αποτελέσματα, ακόμη και όταν οι οδηγίες ήταν πολύ περιορισμένου φάσματος. Για παράδειγμα, προέκυψε μια θαυμάσια συλλογή από δυναμική, techno μουσική όταν η AI Playlist κλήθηκε να δημιουργήσει μια λίστα τραγουδιών η οποία θα "με κάνει να νοιώσω σαν κυνηγός βρικολάκων από το Blade (1998)" ενώ συνοδεύτηκε και από τον τίτλο "Η Ουσία του Blade", χωρίς να χρειαστεί επιπλέον οδηγία. Η Spotify αναφέρει πως οι χρήστες θα έχουν καλύτερα αποτελέσματα χρησιμοποιώντας οδηγίες που περιέχουν συνδυασμό ειδών μουσικής, διαθέσεων, καλλιτεχνών ή δεκαετιών και ότι μπορούν να χρησιμοποιηθούν αναφορές σε τόπους, ζώα, δραστηριότητες, χαρακτήρες ταινιών, χρώματα, ακόμη και emoji. Η εταιρία αναφέρει πως θα συνεχίσει να βελτιώνει αυτή τη λειτουργία, στην πορεία των επόμενων μηνών. Υπάρχουν, βέβαια, ορισμένοι περιορισμοί που θα πρέπει να έχουν υπόψη τους οι χρήστες: η AI Playlist δεν μπορεί να εμφανίσει αποτελέσματα ακολουθώντας μη μουσικές οδηγίες, όπως για παράδειγμα αναφορές σε τρέχουσες ειδήσεις, ενώ στο μοντέλο εφαρμόζονται μέτρα προκειμένου να ακυρώνονται οδηγίες οι οποίες είναι προσβλητικές. Η AI Playlist είναι ένας πολύ ταχύτερος τρόπος ώστε να δημιουργηθεί μια λίστα, από ό,τι να επιλέξει κανείς ένα προς ένα τα τραγούδια, ενώ μπορεί να λειτουργήσει και ως εργαλείο ανακάλυψης άλλων μουσικών προτάσεων, για εκείνους που θα ήθελαν να ακούσουν νέα κομμάτια τα οποία ακολουθούν μια συγκεκριμένη αισθητική. Ήδη, δηλαδή, η AI Playlist δείχνει πολύ πιο χρήσιμη από ότι ο AI DJ της Spotify, που δημιουργεί μια λίστα βασισμένη στο τι έχει ακούσει προηγουμένως ο χρήστης, με περιορισμένες επιλογές για την τροποποίηση της τελικής πρότασης. Η νέα λειτουργία, πάντως, θα μπορούσε να ήταν ένας από τους παράγοντες που συνέβαλαν στις αυξήσεις τιμών τις οποίες αναμένεται να ανακοινώσει η Spotify αργότερα μέσα στο χρόνο. Μέχρι στιγμής, πάντως, η εταιρία δεν έχει ανακοινώσει πότε προτίθεται να καταστήσει την AI Playlist διαθέσιμη και σε άλλες περιοχές. -

 Σύμφωνα με δημοσιογραφικές πληροφορίες, η εταιρία επενδυτικών κεφαλαίων Gigafund καθώς και ο Στιβ Τζέρβετσον συγκαταλέγονται μεταξύ των επενδυτών που εξετάζουν τη συμμετοχή τους σε αυτό το στάδιο. Οι όροι για τη χρηματοδότηση της xAI δεν είχαν συμφωνηθεί οριστικά και τα σχέδια θα μπορούσαν να μεταβληθούν, σύμφωνα με ρεπορτάζ της Wall Street Journal, στο οποίο επισημαίνεται πως ο τρέχων γύρος συζητήσεων έχει ενταθεί το τελευταίο διάστημα. Τόσο η xAI όσο και το γραφείο του ίδιου του Μασκ δεν προχώρησαν σε κάποιο σχόλιο. Ο Μασκ ίδρυσε την xAI πέρυσι, θέλοντας να προβάλει μια εναλλακτική πρόταση έναντι της OpenAI, η οποία χρηματοδοτείται από τη Microsoft, καθώς και τη Google, η οποία έχει τη στήριξη της Alphabet. Νωρίτερα μέσα στο 2024, ο Μασκ είχε διαψεύσει ότι η xAI βρισκόταν σε συζητήσεις με επενδυτές, επιχειρώντας να εξασφαλίσει κεφάλαια, απαντώντας σε τότε ρεπορτάζ που ήθελαν την εταιρία του να επιδιώκει να συγκεντρώσει έως και 6 δισεκατομμύρια δολάρια. Υπενθυμίζεται ότι τον Ιανουάριο οι Financial Times σε ρεπορτάζ τους ανέφεραν ότι η xAI συζητούσε με επενδυτές, έχοντας ως βάση μια αποτίμηση της τάξης των 20 δισεκατομμυρίων δολαρίων. "Η xAI δεν συγκεντρώνει κεφάλαια και δεν είχα απολύτως καμία συζήτηση με τον οποιονδήποτε για το θέμα αυτό", είχε δηλώσει τότε ο Μασκ. Το Μάρτιο, η xAI προχώρησε στη διάθεση μιας βελτιωμένης έκδοσης του chatbot Grok, θέλοντας να προωθήσει την αντιπρόταση που αναπτύσσει έναντι του ChatGPT της OpenAI. Το chatbot είναι αυτή τη στιγμή διαθέσιμο σε ορισμένους χρήστες του Χ. Ο λόγος που ο Μασκ ενδεχομένως έχει μια δυσκολία να παραδεχτεί ότι αναζητά τρίτους επενδυτές, πέρα από τα κεφάλαια που διοχετεύει στην xAI από την προσωπική του περιουσία, είναι πως εδώ και καιρό βρίσκεται σε δημόσια αντιπαράθεση με την OpenAI, εταιρία της οποίας υπήρξε συνιδρυτής προ ετών και που πλέον κατηγορεί ότι "πρόδωσε" την αρχική, μη κερδοσκοπική αποστολή της. Προφανώς, όλοι οι επενδυτές που θα διαθέσουν δισεκατομμύρια δολάρια προκειμένου να ενισχύσουν την xAI σε έναν τομέα o oποίος εξακολουθεί να συγκεντρώνει τεράστιο επενδυτικό ενδιαφέρον, δεν πρόκειται να το κάνουν "μη κερδοσκοπικά", επομένως ακόμη και ο Μασκ θα δυσκολευόταν να δικαιολογήσει μια τόσο θεαματική αλλαγή κατεύθυνσης, τόσο σύντομα μετά την κόντρα που ο ίδιος επέλεξε να δημοσιοποιήσει με την OpenAI, όταν αποφάσισε να κινηθεί νομικά εναντίον της.
Σύμφωνα με δημοσιογραφικές πληροφορίες, η εταιρία επενδυτικών κεφαλαίων Gigafund καθώς και ο Στιβ Τζέρβετσον συγκαταλέγονται μεταξύ των επενδυτών που εξετάζουν τη συμμετοχή τους σε αυτό το στάδιο. Οι όροι για τη χρηματοδότηση της xAI δεν είχαν συμφωνηθεί οριστικά και τα σχέδια θα μπορούσαν να μεταβληθούν, σύμφωνα με ρεπορτάζ της Wall Street Journal, στο οποίο επισημαίνεται πως ο τρέχων γύρος συζητήσεων έχει ενταθεί το τελευταίο διάστημα. Τόσο η xAI όσο και το γραφείο του ίδιου του Μασκ δεν προχώρησαν σε κάποιο σχόλιο. Ο Μασκ ίδρυσε την xAI πέρυσι, θέλοντας να προβάλει μια εναλλακτική πρόταση έναντι της OpenAI, η οποία χρηματοδοτείται από τη Microsoft, καθώς και τη Google, η οποία έχει τη στήριξη της Alphabet. Νωρίτερα μέσα στο 2024, ο Μασκ είχε διαψεύσει ότι η xAI βρισκόταν σε συζητήσεις με επενδυτές, επιχειρώντας να εξασφαλίσει κεφάλαια, απαντώντας σε τότε ρεπορτάζ που ήθελαν την εταιρία του να επιδιώκει να συγκεντρώσει έως και 6 δισεκατομμύρια δολάρια. Υπενθυμίζεται ότι τον Ιανουάριο οι Financial Times σε ρεπορτάζ τους ανέφεραν ότι η xAI συζητούσε με επενδυτές, έχοντας ως βάση μια αποτίμηση της τάξης των 20 δισεκατομμυρίων δολαρίων. "Η xAI δεν συγκεντρώνει κεφάλαια και δεν είχα απολύτως καμία συζήτηση με τον οποιονδήποτε για το θέμα αυτό", είχε δηλώσει τότε ο Μασκ. Το Μάρτιο, η xAI προχώρησε στη διάθεση μιας βελτιωμένης έκδοσης του chatbot Grok, θέλοντας να προωθήσει την αντιπρόταση που αναπτύσσει έναντι του ChatGPT της OpenAI. Το chatbot είναι αυτή τη στιγμή διαθέσιμο σε ορισμένους χρήστες του Χ. Ο λόγος που ο Μασκ ενδεχομένως έχει μια δυσκολία να παραδεχτεί ότι αναζητά τρίτους επενδυτές, πέρα από τα κεφάλαια που διοχετεύει στην xAI από την προσωπική του περιουσία, είναι πως εδώ και καιρό βρίσκεται σε δημόσια αντιπαράθεση με την OpenAI, εταιρία της οποίας υπήρξε συνιδρυτής προ ετών και που πλέον κατηγορεί ότι "πρόδωσε" την αρχική, μη κερδοσκοπική αποστολή της. Προφανώς, όλοι οι επενδυτές που θα διαθέσουν δισεκατομμύρια δολάρια προκειμένου να ενισχύσουν την xAI σε έναν τομέα o oποίος εξακολουθεί να συγκεντρώνει τεράστιο επενδυτικό ενδιαφέρον, δεν πρόκειται να το κάνουν "μη κερδοσκοπικά", επομένως ακόμη και ο Μασκ θα δυσκολευόταν να δικαιολογήσει μια τόσο θεαματική αλλαγή κατεύθυνσης, τόσο σύντομα μετά την κόντρα που ο ίδιος επέλεξε να δημοσιοποιήσει με την OpenAI, όταν αποφάσισε να κινηθεί νομικά εναντίον της. -
Η εξέλιξη αυτή θα οδηγήσει την αποτίμηση της εταιρίας στα 18 δισεκατομμύρια δολάρια, καθώς ο τομέας της τεχνητής νοημοσύνης συνεχίζει να συγκεντρώνει εξαιρετικό επενδυτικό ενδιαφέρον. Σύμφωνα με δημοσιογραφικές πληροφορίες, η εταιρία επενδυτικών κεφαλαίων Gigafund καθώς και ο Στιβ Τζέρβετσον συγκαταλέγονται μεταξύ των επενδυτών που εξετάζουν τη συμμετοχή τους σε αυτό το στάδιο. Οι όροι για τη χρηματοδότηση της xAI δεν είχαν συμφωνηθεί οριστικά και τα σχέδια θα μπορούσαν να μεταβληθούν, σύμφωνα με ρεπορτάζ της Wall Street Journal, στο οποίο επισημαίνεται πως ο τρέχων γύρος συζητήσεων έχει ενταθεί το τελευταίο διάστημα. Τόσο η xAI όσο και το γραφείο του ίδιου του Μασκ δεν προχώρησαν σε κάποιο σχόλιο. Ο Μασκ ίδρυσε την xAI πέρυσι, θέλοντας να προβάλει μια εναλλακτική πρόταση έναντι της OpenAI, η οποία χρηματοδοτείται από τη Microsoft, καθώς και τη Google, η οποία έχει τη στήριξη της Alphabet. Νωρίτερα μέσα στο 2024, ο Μασκ είχε διαψεύσει ότι η xAI βρισκόταν σε συζητήσεις με επενδυτές, επιχειρώντας να εξασφαλίσει κεφάλαια, απαντώντας σε τότε ρεπορτάζ που ήθελαν την εταιρία του να επιδιώκει να συγκεντρώσει έως και 6 δισεκατομμύρια δολάρια. Υπενθυμίζεται ότι τον Ιανουάριο οι Financial Times σε ρεπορτάζ τους ανέφεραν ότι η xAI συζητούσε με επενδυτές, έχοντας ως βάση μια αποτίμηση της τάξης των 20 δισεκατομμυρίων δολαρίων. "Η xAI δεν συγκεντρώνει κεφάλαια και δεν είχα απολύτως καμία συζήτηση με τον οποιονδήποτε για το θέμα αυτό", είχε δηλώσει τότε ο Μασκ. Το Μάρτιο, η xAI προχώρησε στη διάθεση μιας βελτιωμένης έκδοσης του chatbot Grok, θέλοντας να προωθήσει την αντιπρόταση που αναπτύσσει έναντι του ChatGPT της OpenAI. Το chatbot είναι αυτή τη στιγμή διαθέσιμο σε ορισμένους χρήστες του Χ. Ο λόγος που ο Μασκ ενδεχομένως έχει μια δυσκολία να παραδεχτεί ότι αναζητά τρίτους επενδυτές, πέρα από τα κεφάλαια που διοχετεύει στην xAI από την προσωπική του περιουσία, είναι πως εδώ και καιρό βρίσκεται σε δημόσια αντιπαράθεση με την OpenAI, εταιρία της οποίας υπήρξε συνιδρυτής προ ετών και που πλέον κατηγορεί ότι "πρόδωσε" την αρχική, μη κερδοσκοπική αποστολή της. Προφανώς, όλοι οι επενδυτές που θα διαθέσουν δισεκατομμύρια δολάρια προκειμένου να ενισχύσουν την xAI σε έναν τομέα o oποίος εξακολουθεί να συγκεντρώνει τεράστιο επενδυτικό ενδιαφέρον, δεν πρόκειται να το κάνουν "μη κερδοσκοπικά", επομένως ακόμη και ο Μασκ θα δυσκολευόταν να δικαιολογήσει μια τόσο θεαματική αλλαγή κατεύθυνσης, τόσο σύντομα μετά την κόντρα που ο ίδιος επέλεξε να δημοσιοποιήσει με την OpenAI, όταν αποφάσισε να κινηθεί νομικά εναντίον της. Διαβάστε ολόκληρο το άρθρο
-
 Σύμφωνα με δημοσιογραφικές πληροφορίες, η Microsoft έχει ξεκινήσει ήδη τις δοκιμές πάνω σε έναν "ΑΙ χαρακτήρα" ο οποίος κινεί το πρόσωπό του όταν απαντά σε ερωτήσεις σχετικά με την υποστήριξη λειτουργιών του Xbox. Το chatbot αυτό εντάσσεται σε μια ευρύτερη προσπάθεια του τεχνολογικού κολοσσού να ενσωματώσει την τεχνητή νοημοσύνη στην πλατφόρμα του Xbox και τις παρεχόμενες υπηρεσίες. Το chatbot έχει τη δυνατότητα να επικοινωνεί με το υλικό υποστήριξης του δικτύου και του ευρύτερου οικοσυστήματος του Xbox και μπορεί, εκτός του να απαντά σε ερωτήσεις, να επεξεργάζεται αιτήματα επιστροφής χρημάτων, από την ιστοσελίδα τεχνικής υποστήριξης της Microsoft. Το τελευταίο διάστημα η Microsoft φαίνεται πως έχει διευρύνει τον αριθμό των ανθρώπων που έχουν δοκιμαστική πρόσβαση στο chatbot, το οποίο κάποια στιγμή θα μπορούσε να αναλάβει τη διαχείριση ερωτημάτων από το σύνολο των χρηστών του Xbox. Μάλιστα, η Microsoft επιβεβαίωσε στο Verge την ύπαρξη του chatbot. Η Microsoft διαθέτει ήδη το Azure AI Bot Service, το οποίο χρησιμοποιούν εταιρίες όπως η Vodafone, η PwC και άλλες προκειμένου να δημιουργήσουν bots εξυπηρέτησης των πελατών τους. Το Xbox chatbot ξεκινά ρωτώντας τους χρήστες "Πώς μπορώ να βοηθήσω σήμερα;" και έχει τη δυνατότητα να απαντήσει γρήγορα σε ερωτήματα τα οποία κινούνται σε ένα ευρύ φάσμα, από προβλήματα λειτουργίας στο Xbox μέχρι τη διευθέτηση ζητημάτων που αφορούν τις συνδρομές. Σύμφωνα με τις ίδιες δημοσιογραφικές πηγές, το chatbot δοκιμάζεται εσωτερικά στη Microsoft για τη διαχείριση ερωτημάτων που αφορούν τη συνδρομητική υπηρεσία φιλοξενίας διακομιστών Minecraft Realms. H Microsoft εξετάζει επίσης το ενδεχόμενο να δημιουργήσει chatbot βασισμένα στην τεχνητή νοημοσύνη τα οποία θα αναλάβουν την ασφάλεια και το συντονισμό της κοινότητας, μεταξύ των οποίων και της πλατφόρμας του Xbox, ώστε να βοηθήσουν με τη διαχείρηση των διαδικασιών έφεσης κάποιας απόφασης. Η Microsoft εξετάζει επίσης το πώς θα μπορούσε να προσθέσει βοηθούς τεχνητής νοημοσύνης στα παιχνίδια, στους οποίους θα έχουν πρόσβαση οι χρήστες καθώς παίζουν. Νωρίτερα μέσα στη χρονιά, στελέχη της Microsoft περιέγραψαν το όραμα ενός "Χbox Παντού", που περιλάμβανε καινοτομίες στον τομέα της τεχνητής νοημοσύνης ως βασικό στοιχείο αυτού του φιλόδοξου στόχου, παράλληλα με ένα οικοσύστημα και μια πλατφόρμα Xbox που επιτρέπει στους χρήστες να παίζουν όπου θέλουν. Η Microsoft άφησε να εννοηθεί ότι ετοιμάζει ένα εξαιρετικά ισχυρό Xbox νέας γενιάς, λίγες μέρες μετά από εκείνη τη συνάντηση, με τη Σάρα Μποντ, πρόεδρο του Xbox, να υπόσχεται "το μεγαλύτερο τεχνολογικό άλμα που είδατε ποτέ από μία γενιά εξοπλισμού στην επόμενη". Εικάζεται πως το άλμα αυτό περιλαμβάνει και την τεχνητή νοημοσύνη. Την ίδια ώρα, η Sony φημολογείται ότι ετοιμάζει να παρουσιάσει το PS5 Pro, μέσα στο χρόνο, που θα διαθέτει τεχνολογία upscaling παρόμοια με το DLSS της Nvidia ή το FSR της AMD. Το upscaling με τη χρήση τεχνητής νοημοσύνης δεν έχει υιοθετηθεί ακόμη ευρέως, με το Immortals of Aveum να αναμένεται να αποτελέσει το πρώτο παιχνίδι για κονσόλα που θα ενσωματώνει το FSR 3 της AMD. Προφανώς, η Microsoft δεν θέλει να μείνει πίσω, σε σχέση με τις κινήσεις στις οποίες προχωρά η Sony στον τομέα της τεχνητής νοημοσύνης.
Σύμφωνα με δημοσιογραφικές πληροφορίες, η Microsoft έχει ξεκινήσει ήδη τις δοκιμές πάνω σε έναν "ΑΙ χαρακτήρα" ο οποίος κινεί το πρόσωπό του όταν απαντά σε ερωτήσεις σχετικά με την υποστήριξη λειτουργιών του Xbox. Το chatbot αυτό εντάσσεται σε μια ευρύτερη προσπάθεια του τεχνολογικού κολοσσού να ενσωματώσει την τεχνητή νοημοσύνη στην πλατφόρμα του Xbox και τις παρεχόμενες υπηρεσίες. Το chatbot έχει τη δυνατότητα να επικοινωνεί με το υλικό υποστήριξης του δικτύου και του ευρύτερου οικοσυστήματος του Xbox και μπορεί, εκτός του να απαντά σε ερωτήσεις, να επεξεργάζεται αιτήματα επιστροφής χρημάτων, από την ιστοσελίδα τεχνικής υποστήριξης της Microsoft. Το τελευταίο διάστημα η Microsoft φαίνεται πως έχει διευρύνει τον αριθμό των ανθρώπων που έχουν δοκιμαστική πρόσβαση στο chatbot, το οποίο κάποια στιγμή θα μπορούσε να αναλάβει τη διαχείριση ερωτημάτων από το σύνολο των χρηστών του Xbox. Μάλιστα, η Microsoft επιβεβαίωσε στο Verge την ύπαρξη του chatbot. Η Microsoft διαθέτει ήδη το Azure AI Bot Service, το οποίο χρησιμοποιούν εταιρίες όπως η Vodafone, η PwC και άλλες προκειμένου να δημιουργήσουν bots εξυπηρέτησης των πελατών τους. Το Xbox chatbot ξεκινά ρωτώντας τους χρήστες "Πώς μπορώ να βοηθήσω σήμερα;" και έχει τη δυνατότητα να απαντήσει γρήγορα σε ερωτήματα τα οποία κινούνται σε ένα ευρύ φάσμα, από προβλήματα λειτουργίας στο Xbox μέχρι τη διευθέτηση ζητημάτων που αφορούν τις συνδρομές. Σύμφωνα με τις ίδιες δημοσιογραφικές πηγές, το chatbot δοκιμάζεται εσωτερικά στη Microsoft για τη διαχείριση ερωτημάτων που αφορούν τη συνδρομητική υπηρεσία φιλοξενίας διακομιστών Minecraft Realms. H Microsoft εξετάζει επίσης το ενδεχόμενο να δημιουργήσει chatbot βασισμένα στην τεχνητή νοημοσύνη τα οποία θα αναλάβουν την ασφάλεια και το συντονισμό της κοινότητας, μεταξύ των οποίων και της πλατφόρμας του Xbox, ώστε να βοηθήσουν με τη διαχείρηση των διαδικασιών έφεσης κάποιας απόφασης. Η Microsoft εξετάζει επίσης το πώς θα μπορούσε να προσθέσει βοηθούς τεχνητής νοημοσύνης στα παιχνίδια, στους οποίους θα έχουν πρόσβαση οι χρήστες καθώς παίζουν. Νωρίτερα μέσα στη χρονιά, στελέχη της Microsoft περιέγραψαν το όραμα ενός "Χbox Παντού", που περιλάμβανε καινοτομίες στον τομέα της τεχνητής νοημοσύνης ως βασικό στοιχείο αυτού του φιλόδοξου στόχου, παράλληλα με ένα οικοσύστημα και μια πλατφόρμα Xbox που επιτρέπει στους χρήστες να παίζουν όπου θέλουν. Η Microsoft άφησε να εννοηθεί ότι ετοιμάζει ένα εξαιρετικά ισχυρό Xbox νέας γενιάς, λίγες μέρες μετά από εκείνη τη συνάντηση, με τη Σάρα Μποντ, πρόεδρο του Xbox, να υπόσχεται "το μεγαλύτερο τεχνολογικό άλμα που είδατε ποτέ από μία γενιά εξοπλισμού στην επόμενη". Εικάζεται πως το άλμα αυτό περιλαμβάνει και την τεχνητή νοημοσύνη. Την ίδια ώρα, η Sony φημολογείται ότι ετοιμάζει να παρουσιάσει το PS5 Pro, μέσα στο χρόνο, που θα διαθέτει τεχνολογία upscaling παρόμοια με το DLSS της Nvidia ή το FSR της AMD. Το upscaling με τη χρήση τεχνητής νοημοσύνης δεν έχει υιοθετηθεί ακόμη ευρέως, με το Immortals of Aveum να αναμένεται να αποτελέσει το πρώτο παιχνίδι για κονσόλα που θα ενσωματώνει το FSR 3 της AMD. Προφανώς, η Microsoft δεν θέλει να μείνει πίσω, σε σχέση με τις κινήσεις στις οποίες προχωρά η Sony στον τομέα της τεχνητής νοημοσύνης. -
Έχουν ξεκινήσει ήδη οι εσωτερικές δοκιμές του chatbot που θα μπορεί να βοηθήσει στην τεχνική υποστήριξη αλλά και την επιστροφή χρημάτων από αγορές παιχνιδιών. Σύμφωνα με δημοσιογραφικές πληροφορίες, η Microsoft έχει ξεκινήσει ήδη τις δοκιμές πάνω σε έναν "ΑΙ χαρακτήρα" ο οποίος κινεί το πρόσωπό του όταν απαντά σε ερωτήσεις σχετικά με την υποστήριξη λειτουργιών του Xbox. Το chatbot αυτό εντάσσεται σε μια ευρύτερη προσπάθεια του τεχνολογικού κολοσσού να ενσωματώσει την τεχνητή νοημοσύνη στην πλατφόρμα του Xbox και τις παρεχόμενες υπηρεσίες. Το chatbot έχει τη δυνατότητα να επικοινωνεί με το υλικό υποστήριξης του δικτύου και του ευρύτερου οικοσυστήματος του Xbox και μπορεί, εκτός του να απαντά σε ερωτήσεις, να επεξεργάζεται αιτήματα επιστροφής χρημάτων, από την ιστοσελίδα τεχνικής υποστήριξης της Microsoft. Το τελευταίο διάστημα η Microsoft φαίνεται πως έχει διευρύνει τον αριθμό των ανθρώπων που έχουν δοκιμαστική πρόσβαση στο chatbot, το οποίο κάποια στιγμή θα μπορούσε να αναλάβει τη διαχείριση ερωτημάτων από το σύνολο των χρηστών του Xbox. Μάλιστα, η Microsoft επιβεβαίωσε στο Verge την ύπαρξη του chatbot. Η Microsoft διαθέτει ήδη το Azure AI Bot Service, το οποίο χρησιμοποιούν εταιρίες όπως η Vodafone, η PwC και άλλες προκειμένου να δημιουργήσουν bots εξυπηρέτησης των πελατών τους. Το Xbox chatbot ξεκινά ρωτώντας τους χρήστες "Πώς μπορώ να βοηθήσω σήμερα;" και έχει τη δυνατότητα να απαντήσει γρήγορα σε ερωτήματα τα οποία κινούνται σε ένα ευρύ φάσμα, από προβλήματα λειτουργίας στο Xbox μέχρι τη διευθέτηση ζητημάτων που αφορούν τις συνδρομές. Σύμφωνα με τις ίδιες δημοσιογραφικές πηγές, το chatbot δοκιμάζεται εσωτερικά στη Microsoft για τη διαχείριση ερωτημάτων που αφορούν τη συνδρομητική υπηρεσία φιλοξενίας διακομιστών Minecraft Realms. H Microsoft εξετάζει επίσης το ενδεχόμενο να δημιουργήσει chatbot βασισμένα στην τεχνητή νοημοσύνη τα οποία θα αναλάβουν την ασφάλεια και το συντονισμό της κοινότητας, μεταξύ των οποίων και της πλατφόρμας του Xbox, ώστε να βοηθήσουν με τη διαχείρηση των διαδικασιών έφεσης κάποιας απόφασης. Η Microsoft εξετάζει επίσης το πώς θα μπορούσε να προσθέσει βοηθούς τεχνητής νοημοσύνης στα παιχνίδια, στους οποίους θα έχουν πρόσβαση οι χρήστες καθώς παίζουν. Νωρίτερα μέσα στη χρονιά, στελέχη της Microsoft περιέγραψαν το όραμα ενός "Χbox Παντού", που περιλάμβανε καινοτομίες στον τομέα της τεχνητής νοημοσύνης ως βασικό στοιχείο αυτού του φιλόδοξου στόχου, παράλληλα με ένα οικοσύστημα και μια πλατφόρμα Xbox που επιτρέπει στους χρήστες να παίζουν όπου θέλουν. Η Microsoft άφησε να εννοηθεί ότι ετοιμάζει ένα εξαιρετικά ισχυρό Xbox νέας γενιάς, λίγες μέρες μετά από εκείνη τη συνάντηση, με τη Σάρα Μποντ, πρόεδρο του Xbox, να υπόσχεται "το μεγαλύτερο τεχνολογικό άλμα που είδατε ποτέ από μία γενιά εξοπλισμού στην επόμενη". Εικάζεται πως το άλμα αυτό περιλαμβάνει και την τεχνητή νοημοσύνη. Την ίδια ώρα, η Sony φημολογείται ότι ετοιμάζει να παρουσιάσει το PS5 Pro, μέσα στο χρόνο, που θα διαθέτει τεχνολογία upscaling παρόμοια με το DLSS της Nvidia ή το FSR της AMD. Το upscaling με τη χρήση τεχνητής νοημοσύνης δεν έχει υιοθετηθεί ακόμη ευρέως, με το Immortals of Aveum να αναμένεται να αποτελέσει το πρώτο παιχνίδι για κονσόλα που θα ενσωματώνει το FSR 3 της AMD. Προφανώς, η Microsoft δεν θέλει να μείνει πίσω, σε σχέση με τις κινήσεις στις οποίες προχωρά η Sony στον τομέα της τεχνητής νοημοσύνης. Διαβάστε ολόκληρο το άρθρο
-
Το μοντέλο, με την επωνυμία Voice Generation, αναπτύσσεται από τα τέλη του 2022 και είναι αυτό πάνω στο οποίο βασίζεται η λειτουργία ανάγνωσης που διαθέτει το ChatGPT. Η OpenAI προσφέρει περιορισμένη πρόσβαση σε μια πλατφόρμα μετατροπής κειμένου σε φωνή την οποία έχει αναπτύξει, με την επωνυμία Voice Engine, η οποία μπορεί να δημιουργήσει συνθετική φωνή, βασισμένη σε ηχογραφημένο απόσπασμα διάρκειας μόλις 15 δευτερολέπτων. Η φωνή αυτή είναι σε θέση να αναγνώσει γραπτές οδηγίες στην ίδια γλώσσα όπως ο πραγματικός ομιλητής ή σε μια σειρά από άλλες γλώσσες. "Αυτές οι μικρής κλίμακας εφαρμογές μας βοηθούν να καταλήξουμε στην προσέγγιση, τις ασφαλιστικές δικλείδες και στον τρόπο που αντιλαμβανόμαστε το πώς θα μπορούσε να χρησιμοποιηθεί η Voice Engine για καλούς σκόπους, σε μια σειρά τομέων", αναφέρει η OpenAI σε ανάρτηση στο ιστολόγιό της. Μεταξύ των εταιριών που έχουν πρόσβαση στην πλατφόρμα συγκαταλέγεται και εταιρία εκπαιδευτικής τεχνολογίας Age of Learning, η πλατφόρμα μυθοπλασίας HeyGen, η πρωτοπόρος στον τομέα του λογισμικού για εφαρμογές υγείας Dimagi, η Livox που δημιουργεί εφαρμογές επικοινωνίας με τη χρήση τεχνητής νοημοσύνης, καθώς και η Lifespan, η οποία αναπτύσσει συστήματα υγείας. Στα παρακάτω δείγματα, τα οποία δημοσίευσε η OpenAI, μπορεί κανείς να διαπιστώσει πώς αξιοποιεί η Age of Learning την τεχνολογία αυτή προκειμένου να δημιουργήσει εκφωνήσεις προεπιλεγμένου υλικού αλλά και για την ανάγνωση "προσωποποιημένων απαντήσεων σε πραγματικό χρόνο", γραμμένες από το GPT-4. Πρώτα, το ηχητικό απόσπασμα στα Αγγλικά, που αποτελεί τη βάση: age_of_learning_reference.mp3 Κι εδώ, έχουμε τα τρία ηχητικά αποσπάσματα που δημιουργήθηκαν από την τεχνητή νοημοσύνη, βασισμένα στο παραπάνω δείγμα: age_of_learning_rainforest.mp3 age_of_learning_reading.mp3 age_of_learning_chemistry.mp3 Η OpenAI ανέφερε πως ξεκίνησε την ανάπτυξη της Voice Engine το 2022 και ότι η τεχνολογία αυτή έχει υποστηρίξει ήδη φωνές που χρησιμοποιούνται στη μετατροπή κειμένου σε φωνή, καθώς και τη λειτουργία Read Aloud που διαθέτει το ChatGPT. Σε συνέντευξη που παραχώρησε το TechCrunch, ο Τζεφ Χάρις, μέλος της ομάδας ανάπτυξης της Voice Engine, ανέφερε ότι το μοντέλο εκπαιδεύτηκε χρησιμοποιώντας "συνδυασμό δημόσια διαθέσιμων δεδομένων και νόμιμα παραχωρημένου υλικού". Η OpenAI δήλωσε ότι το μοντέλο θα διατεθεί αρχικά σε περίπου 10 εταιρίες. Η μετατροπή κειμένου σε ήχο μέσω τεχνητής νοημοσύνης αποτελεί έναν τομέα της συγκεκριμένης τεχνολογίας που εξακολουθεί να εξελίσσεται. Παρότι το ενδιαφέρον εστιάζεται κυρίως σε ορχηστρικούς ή φυσικούς ήχους, έχουν καταγραφεί προσπάθειες και στο κομμάτι της δημιουργίας φωνής, αλλά σε πολύ μικρότερο βαθμό, εν μέρει λόγω των ζητημάτων που έθεσε η ίδια η OpenAI, ως προς το πώς θα χρησιμοποιούταν αυτό το υλικό. Την ίδια στιγμή, η αμερικανική κυβέρνηση επιχειρεί να περιορίσει την κακόβουλη χρήση της τεχνολογίας δημιουργίας φωνής μέσω τεχνητής νοημοσύνης. Μόλις τον περασμένο μήνα, η Ομοσπονδιακή Επιτροπή Επικοινωνιών απαγόρευσε τις αυτόματες κλήσεις με τη χρήση φωνών που δημιουργήθηκαν από μοντέλα τεχνητής νοημοσύνης, μετά από καταγγελίες ότι πολίτες δέχονταν τηλεφωνήματα όπου χρησιμοποιούνταν η κλωνοποιημένη φωνή του προέδρου Μπάιντεν, με τα οποία καλούνταν οι ψηφοφόροι να μην προσέλθουν στις εκλογές. Σύμφωνα με την OpenAI, οι εταίροι της συμφώνησαν να τηρήσουν το πλαίσιο χρήσης που διαμόρφωσε η εταιρία και ορίζει πως το υλικό δεν θα χρησιμοποιείται για την προώθηση μηνυμάτων από άτομα ή οργανισμούς χωρίς την πρότερη συγκατάθεσή τους. Παράλληλα, οι εταίροι υποχρεούνται να λάβουν τη "ρητή και ενήμερη συναίνεση" του αρχικού ομιλητή, να μη δημιουργήσουν τρόπους ώστε οι χρήστες να μπορούν να σχηματίζουν δικές τους φωνές και να ενημερώνουν τους ακροατές ότι οι φωνές που ακούγονται έχουν δημιουργηθεί από πρόγραμμα τεχνητής νοημοσύνης. Η OpenAI προσέθεσε επίσης την ενσωμάτων υδατογραφημάτων στα ηχητικά αποσπάσματα ώστε να εντοπίζεται η αρχική προέλευσή τους και να παρακολουθείται ενεργά το πού χρησιμοποιείται το υλικό. Η OpenAI πρότεινε διάφορα βήματα που θεωρεί πως θα μπορούσαν να περιορίσουν τους κινδύνους γύρω από τέτοιου είδους εργαλεία, μεταξύ των οποίων τη σταδιακή αφαίρεση της φωνητικής πρόσβασης σε τραπεζικούς λογαριασμούς, πολιτικές για την προστασία της χρήσης της φωνής των ανθρώπων σε μοντέλα τεχνητής νοημοσύνης, διεξοδικότερη ενημέρωση για την κακόβουλη χρήση της τεχνητής νοημοσύνης και την ανάπτυξη συστημάτων παρακολούθησης του πού χρησιμοποιείται το περιεχόμενο που έχει δημιουργηθεί από μοντέλα τεχνητής νοημοσύνης. Διαβάστε ολόκληρο το άρθρο
-
 Η OpenAI προσφέρει περιορισμένη πρόσβαση σε μια πλατφόρμα μετατροπής κειμένου σε φωνή την οποία έχει αναπτύξει, με την επωνυμία Voice Engine, η οποία μπορεί να δημιουργήσει συνθετική φωνή, βασισμένη σε ηχογραφημένο απόσπασμα διάρκειας μόλις 15 δευτερολέπτων. Η φωνή αυτή είναι σε θέση να αναγνώσει γραπτές οδηγίες στην ίδια γλώσσα όπως ο πραγματικός ομιλητής ή σε μια σειρά από άλλες γλώσσες. "Αυτές οι μικρής κλίμακας εφαρμογές μας βοηθούν να καταλήξουμε στην προσέγγιση, τις ασφαλιστικές δικλείδες και στον τρόπο που αντιλαμβανόμαστε το πώς θα μπορούσε να χρησιμοποιηθεί η Voice Engine για καλούς σκόπους, σε μια σειρά τομέων", αναφέρει η OpenAI σε ανάρτηση στο ιστολόγιό της. Μεταξύ των εταιριών που έχουν πρόσβαση στην πλατφόρμα συγκαταλέγεται και εταιρία εκπαιδευτικής τεχνολογίας Age of Learning, η πλατφόρμα μυθοπλασίας HeyGen, η πρωτοπόρος στον τομέα του λογισμικού για εφαρμογές υγείας Dimagi, η Livox που δημιουργεί εφαρμογές επικοινωνίας με τη χρήση τεχνητής νοημοσύνης, καθώς και η Lifespan, η οποία αναπτύσσει συστήματα υγείας. Στα παρακάτω δείγματα, τα οποία δημοσίευσε η OpenAI, μπορεί κανείς να διαπιστώσει πώς αξιοποιεί η Age of Learning την τεχνολογία αυτή προκειμένου να δημιουργήσει εκφωνήσεις προεπιλεγμένου υλικού αλλά και για την ανάγνωση "προσωποποιημένων απαντήσεων σε πραγματικό χρόνο", γραμμένες από το GPT-4. Πρώτα, το ηχητικό απόσπασμα στα Αγγλικά, που αποτελεί τη βάση: age_of_learning_reference.mp3 Κι εδώ, έχουμε τα τρία ηχητικά αποσπάσματα που δημιουργήθηκαν από την τεχνητή νοημοσύνη, βασισμένα στο παραπάνω δείγμα: age_of_learning_rainforest.mp3 age_of_learning_reading.mp3 age_of_learning_chemistry.mp3 Η OpenAI ανέφερε πως ξεκίνησε την ανάπτυξη της Voice Engine το 2022 και ότι η τεχνολογία αυτή έχει υποστηρίξει ήδη φωνές που χρησιμοποιούνται στη μετατροπή κειμένου σε φωνή, καθώς και τη λειτουργία Read Aloud που διαθέτει το ChatGPT. Σε συνέντευξη που παραχώρησε το TechCrunch, ο Τζεφ Χάρις, μέλος της ομάδας ανάπτυξης της Voice Engine, ανέφερε ότι το μοντέλο εκπαιδεύτηκε χρησιμοποιώντας "συνδυασμό δημόσια διαθέσιμων δεδομένων και νόμιμα παραχωρημένου υλικού". Η OpenAI δήλωσε ότι το μοντέλο θα διατεθεί αρχικά σε περίπου 10 εταιρίες. Η μετατροπή κειμένου σε ήχο μέσω τεχνητής νοημοσύνης αποτελεί έναν τομέα της συγκεκριμένης τεχνολογίας που εξακολουθεί να εξελίσσεται. Παρότι το ενδιαφέρον εστιάζεται κυρίως σε ορχηστρικούς ή φυσικούς ήχους, έχουν καταγραφεί προσπάθειες και στο κομμάτι της δημιουργίας φωνής, αλλά σε πολύ μικρότερο βαθμό, εν μέρει λόγω των ζητημάτων που έθεσε η ίδια η OpenAI, ως προς το πώς θα χρησιμοποιούταν αυτό το υλικό. Την ίδια στιγμή, η αμερικανική κυβέρνηση επιχειρεί να περιορίσει την κακόβουλη χρήση της τεχνολογίας δημιουργίας φωνής μέσω τεχνητής νοημοσύνης. Μόλις τον περασμένο μήνα, η Ομοσπονδιακή Επιτροπή Επικοινωνιών απαγόρευσε τις αυτόματες κλήσεις με τη χρήση φωνών που δημιουργήθηκαν από μοντέλα τεχνητής νοημοσύνης, μετά από καταγγελίες ότι πολίτες δέχονταν τηλεφωνήματα όπου χρησιμοποιούνταν η κλωνοποιημένη φωνή του προέδρου Μπάιντεν, με τα οποία καλούνταν οι ψηφοφόροι να μην προσέλθουν στις εκλογές. Σύμφωνα με την OpenAI, οι εταίροι της συμφώνησαν να τηρήσουν το πλαίσιο χρήσης που διαμόρφωσε η εταιρία και ορίζει πως το υλικό δεν θα χρησιμοποιείται για την προώθηση μηνυμάτων από άτομα ή οργανισμούς χωρίς την πρότερη συγκατάθεσή τους. Παράλληλα, οι εταίροι υποχρεούνται να λάβουν τη "ρητή και ενήμερη συναίνεση" του αρχικού ομιλητή, να μη δημιουργήσουν τρόπους ώστε οι χρήστες να μπορούν να σχηματίζουν δικές τους φωνές και να ενημερώνουν τους ακροατές ότι οι φωνές που ακούγονται έχουν δημιουργηθεί από πρόγραμμα τεχνητής νοημοσύνης. Η OpenAI προσέθεσε επίσης την ενσωμάτων υδατογραφημάτων στα ηχητικά αποσπάσματα ώστε να εντοπίζεται η αρχική προέλευσή τους και να παρακολουθείται ενεργά το πού χρησιμοποιείται το υλικό. Η OpenAI πρότεινε διάφορα βήματα που θεωρεί πως θα μπορούσαν να περιορίσουν τους κινδύνους γύρω από τέτοιου είδους εργαλεία, μεταξύ των οποίων τη σταδιακή αφαίρεση της φωνητικής πρόσβασης σε τραπεζικούς λογαριασμούς, πολιτικές για την προστασία της χρήσης της φωνής των ανθρώπων σε μοντέλα τεχνητής νοημοσύνης, διεξοδικότερη ενημέρωση για την κακόβουλη χρήση της τεχνητής νοημοσύνης και την ανάπτυξη συστημάτων παρακολούθησης του πού χρησιμοποιείται το περιεχόμενο που έχει δημιουργηθεί από μοντέλα τεχνητής νοημοσύνης.
Η OpenAI προσφέρει περιορισμένη πρόσβαση σε μια πλατφόρμα μετατροπής κειμένου σε φωνή την οποία έχει αναπτύξει, με την επωνυμία Voice Engine, η οποία μπορεί να δημιουργήσει συνθετική φωνή, βασισμένη σε ηχογραφημένο απόσπασμα διάρκειας μόλις 15 δευτερολέπτων. Η φωνή αυτή είναι σε θέση να αναγνώσει γραπτές οδηγίες στην ίδια γλώσσα όπως ο πραγματικός ομιλητής ή σε μια σειρά από άλλες γλώσσες. "Αυτές οι μικρής κλίμακας εφαρμογές μας βοηθούν να καταλήξουμε στην προσέγγιση, τις ασφαλιστικές δικλείδες και στον τρόπο που αντιλαμβανόμαστε το πώς θα μπορούσε να χρησιμοποιηθεί η Voice Engine για καλούς σκόπους, σε μια σειρά τομέων", αναφέρει η OpenAI σε ανάρτηση στο ιστολόγιό της. Μεταξύ των εταιριών που έχουν πρόσβαση στην πλατφόρμα συγκαταλέγεται και εταιρία εκπαιδευτικής τεχνολογίας Age of Learning, η πλατφόρμα μυθοπλασίας HeyGen, η πρωτοπόρος στον τομέα του λογισμικού για εφαρμογές υγείας Dimagi, η Livox που δημιουργεί εφαρμογές επικοινωνίας με τη χρήση τεχνητής νοημοσύνης, καθώς και η Lifespan, η οποία αναπτύσσει συστήματα υγείας. Στα παρακάτω δείγματα, τα οποία δημοσίευσε η OpenAI, μπορεί κανείς να διαπιστώσει πώς αξιοποιεί η Age of Learning την τεχνολογία αυτή προκειμένου να δημιουργήσει εκφωνήσεις προεπιλεγμένου υλικού αλλά και για την ανάγνωση "προσωποποιημένων απαντήσεων σε πραγματικό χρόνο", γραμμένες από το GPT-4. Πρώτα, το ηχητικό απόσπασμα στα Αγγλικά, που αποτελεί τη βάση: age_of_learning_reference.mp3 Κι εδώ, έχουμε τα τρία ηχητικά αποσπάσματα που δημιουργήθηκαν από την τεχνητή νοημοσύνη, βασισμένα στο παραπάνω δείγμα: age_of_learning_rainforest.mp3 age_of_learning_reading.mp3 age_of_learning_chemistry.mp3 Η OpenAI ανέφερε πως ξεκίνησε την ανάπτυξη της Voice Engine το 2022 και ότι η τεχνολογία αυτή έχει υποστηρίξει ήδη φωνές που χρησιμοποιούνται στη μετατροπή κειμένου σε φωνή, καθώς και τη λειτουργία Read Aloud που διαθέτει το ChatGPT. Σε συνέντευξη που παραχώρησε το TechCrunch, ο Τζεφ Χάρις, μέλος της ομάδας ανάπτυξης της Voice Engine, ανέφερε ότι το μοντέλο εκπαιδεύτηκε χρησιμοποιώντας "συνδυασμό δημόσια διαθέσιμων δεδομένων και νόμιμα παραχωρημένου υλικού". Η OpenAI δήλωσε ότι το μοντέλο θα διατεθεί αρχικά σε περίπου 10 εταιρίες. Η μετατροπή κειμένου σε ήχο μέσω τεχνητής νοημοσύνης αποτελεί έναν τομέα της συγκεκριμένης τεχνολογίας που εξακολουθεί να εξελίσσεται. Παρότι το ενδιαφέρον εστιάζεται κυρίως σε ορχηστρικούς ή φυσικούς ήχους, έχουν καταγραφεί προσπάθειες και στο κομμάτι της δημιουργίας φωνής, αλλά σε πολύ μικρότερο βαθμό, εν μέρει λόγω των ζητημάτων που έθεσε η ίδια η OpenAI, ως προς το πώς θα χρησιμοποιούταν αυτό το υλικό. Την ίδια στιγμή, η αμερικανική κυβέρνηση επιχειρεί να περιορίσει την κακόβουλη χρήση της τεχνολογίας δημιουργίας φωνής μέσω τεχνητής νοημοσύνης. Μόλις τον περασμένο μήνα, η Ομοσπονδιακή Επιτροπή Επικοινωνιών απαγόρευσε τις αυτόματες κλήσεις με τη χρήση φωνών που δημιουργήθηκαν από μοντέλα τεχνητής νοημοσύνης, μετά από καταγγελίες ότι πολίτες δέχονταν τηλεφωνήματα όπου χρησιμοποιούνταν η κλωνοποιημένη φωνή του προέδρου Μπάιντεν, με τα οποία καλούνταν οι ψηφοφόροι να μην προσέλθουν στις εκλογές. Σύμφωνα με την OpenAI, οι εταίροι της συμφώνησαν να τηρήσουν το πλαίσιο χρήσης που διαμόρφωσε η εταιρία και ορίζει πως το υλικό δεν θα χρησιμοποιείται για την προώθηση μηνυμάτων από άτομα ή οργανισμούς χωρίς την πρότερη συγκατάθεσή τους. Παράλληλα, οι εταίροι υποχρεούνται να λάβουν τη "ρητή και ενήμερη συναίνεση" του αρχικού ομιλητή, να μη δημιουργήσουν τρόπους ώστε οι χρήστες να μπορούν να σχηματίζουν δικές τους φωνές και να ενημερώνουν τους ακροατές ότι οι φωνές που ακούγονται έχουν δημιουργηθεί από πρόγραμμα τεχνητής νοημοσύνης. Η OpenAI προσέθεσε επίσης την ενσωμάτων υδατογραφημάτων στα ηχητικά αποσπάσματα ώστε να εντοπίζεται η αρχική προέλευσή τους και να παρακολουθείται ενεργά το πού χρησιμοποιείται το υλικό. Η OpenAI πρότεινε διάφορα βήματα που θεωρεί πως θα μπορούσαν να περιορίσουν τους κινδύνους γύρω από τέτοιου είδους εργαλεία, μεταξύ των οποίων τη σταδιακή αφαίρεση της φωνητικής πρόσβασης σε τραπεζικούς λογαριασμούς, πολιτικές για την προστασία της χρήσης της φωνής των ανθρώπων σε μοντέλα τεχνητής νοημοσύνης, διεξοδικότερη ενημέρωση για την κακόβουλη χρήση της τεχνητής νοημοσύνης και την ανάπτυξη συστημάτων παρακολούθησης του πού χρησιμοποιείται το περιεχόμενο που έχει δημιουργηθεί από μοντέλα τεχνητής νοημοσύνης. -
Ο Σαμ Άλτμαν, διευθύνων σύμβουλος της εταιρίας, συναντήθηκε με ανθρώπους της Universal, της Paramount και της Warner Bros Discovery. Η OpenAI έχει ξεκινήσει σειρά συναντήσεων με στελέχη της αμερικανικής κινηματογραφικής βιομηχανίας, προκειμένου να παρουσιάσει το Sora, ένα εργαλείο δημιουργίας βίντεο με τη χρήση τεχνητής νοημοσύνης, επιχειρώντας παράλληλα να κατευνάσει τις ανησυχίες που θέλουν τη νέα τεχνολογία να συνιστά απειλή για το χώρο. Σύμφωνα με δημοσιογραφικές πληροφορίες, το τελευταίο διάστημα ο Σαλ Άλτμαν, διευθύνων σύμβουλος της εταιρίας, συνοδευόμενος από το Μπραντ Λάιτκαπ, γενικό διευθυντή της OpenAI, παρουσίασαν το Sora σε στελέχη ορισμένων από τα κορυφαία κινηματογραφικά στούντιο. Η νέα αυτή τεχνολογία κέντρισε αρχικά το ενδιαφέρον του Χόλυγουντ από τη στιγμή που η OpenAI δημοσίευσε μια σειρά βίντεο τα οποία δημιούργησε το Sora, τον περασμένο μήνα. Τα κλιπ αυτά προκάλεσαν αίσθηση στο διαδίκτυο και οδήγησαν σε μια ευρύτερη συζήτηση σχετικά με την ενδεχόμενη επίδραση του εργαλείου αυτού και της τεχνολογίας ευρύτερα, στις δημιουργικές βιομηχανίες. "Το Sora προκαλεί τεράστιο ενθουσιασμό", σχολιάζει η αναλύτρια Κλερ Έντερς. "Υπάρχει η αίσθηση πως πρόκειται να φέρει την επανάσταση στον τρόπο που δημιουργούνται οι ταινίες, περιορίζοντας το κόστος παραγωγής αλλά και την ανάγκη προσφυγής στο CGI". sora-1.mp4 Στόχος των συναντήσεων ήταν να βολιδοσκοπηθούν τα στελέχη των κινηματογραφικών στούντιο σχετικά με το πώς θα ήταν σκόπιμο να παρουσιαστεί το Sora. Ορισμένοι από τους συμμετέχοντες σχολίασαν ότι μπορούσαν να φανταστούν το πώς το Sora η ανάλογα εργαλεία τεχνητής νοημοσύνης θα περιόριζαν το κόστος παραγωγής, όμως επισήμαναν ότι η τεχνολογία χρειάζεται περαιτέρω εξέλιξη. Η προσπάθεια της OpenAI να προσεγγίσει τα στούντιο καταγράφεται σε μια ευαίσθητη περίοδο για το Χόλυγουντ. Οι περυσινές, πολύμηνες απεργίες έληξαν όταν η Αμερικανική Ένωση Σεναριογράφων και η Ένωση Ηθοποιών εξασφάλισαν την ενσωμάτωση στα συμβόλαιά τους ριζοσπαστικών ασφαλιστικών δικλείδων έναντι της τεχνητής νοημοσύνης. Φέτος, βρίσκονται ήδη σε εξέλιξη συλλογικές διαπραγματεύσεις με τη Διεθνή Συμμαχία Θεατρικών Εργαζομένων και, όπως στις προηγούμενες περιπτώσεις, το ζήτημα της τεχνητής νοημοσύνης αναμένεται να βρεθεί στο επίκεντρο. Νωρίτερα αυτή την εβδομάδα η OpenAI δημοσίευσε νέα βίντεο με χρήση του Sora, τα οποία δημιούργησαν διάφοροι καλλιτέχνες, μεταξύ των οποίων και ταινίες μικρού μήκους, καθώς και τις εντυπώσεις των δημιουργών από την όλη διαδικασία. Το μοντέλο στόχο έχει να ανταγωνιστεί διάφορες αντίστοιχες προτάσεις άλλων εταιριών, όπως αυτές των Runway, Pika και Stability AI. Τα μοντέλα που προτείνουν οι εταιρίες αυτές είναι ήδη διαθέσιμα για εμπορική χρήση. sora-2.mp4 Το Sora, όμως, δεν έχει κυκλοφορήσει ακόμη επίσημα. Η OpenAI έχει αποφύγει να δώσει συγκεκριμένη ημερομηνία διάθεσης στην αγορά, ενώ δεν έχει συζητήσει και το πλαίσιο υπό το οποίο θα είναι διαθέσιμο. Η εταιρία φέρεται να εξετάζει ακόμη το πώς θα αξιοποιήσει εμπορικά τη συγκεκριμένη τεχνολογία. Δημοσιογραφικές πηγές αναφέρουν ότι η συζήτηση εστιάζει εκτός των άλλων και στα μέτρα ασφαλείας που θα ενσωματωθούν, πριν διατεθεί το Sora ως εμπορικό προϊόν. Παράλληλα, η OpenAI συνεχίζει να βελτιώνει το σύστημα. Επί του παρόντος, το Sora περιορίζεται σε βίντεο διάρκειας κάτω του ενός λεπτού και οι δημιουργίες του έχουν ατέλειες, όπως για παράδειγμα το ότι το γυαλί αναπηδά στο πάτωμα αντί να σπάει ή ότι το μοντέλο προσθέτει περισσευούμενα μέλη σε ανθρώπους και ζώα. Ορισμένα στούντιο εμφανίστηκαν ανοιχτά στο ενδεχόμενο να χρησιμοποιήσουν το Sora για μελλοντικές κινηματογραφικές ή τηλεοπτικές παραγωγές, όμως ακόμη δεν έχουν συζητηθεί οι σχετικές άδειες και συνεργασίες. Επί του παρόντος η OpenAI παρουσιάζει το μοντέλο με "πολύ ελεγχόμενο τρόπο" σε βιομηχανίες που είναι πιθανό να επηρεαστούν αμεσότερα από την άφιξη του νέου εργαλείου. Σύμφωνα με την Έντερς, η υποδοχή από τα στελέχη των στούντιο ήταν σε γενικές γραμμές θετική, καθώς το Sora αντιμετωπίζεται ως "εργαλείο περιορισμού των εξόδων και όχι ως μηχανισμός που θα επιδρούσε στο δημιουργικό ήθος της κινηματογραφικής αφηγηματικής τέχνης". Η OpenAI δεν θέλησε να προβεί σε κάποιο σχόλιο. sora-3.mp4 Διαβάστε ολόκληρο το άρθρο
-
Σε στελέχη του Χόλυγουντ παρουσίασε το Sora η OpenAI
Snoob δημοσίευσε ένα άρθρο στο Artificial Intelligence
 Η OpenAI έχει ξεκινήσει σειρά συναντήσεων με στελέχη της αμερικανικής κινηματογραφικής βιομηχανίας, προκειμένου να παρουσιάσει το Sora, ένα εργαλείο δημιουργίας βίντεο με τη χρήση τεχνητής νοημοσύνης, επιχειρώντας παράλληλα να κατευνάσει τις ανησυχίες που θέλουν τη νέα τεχνολογία να συνιστά απειλή για το χώρο. Σύμφωνα με δημοσιογραφικές πληροφορίες, το τελευταίο διάστημα ο Σαλ Άλτμαν, διευθύνων σύμβουλος της εταιρίας, συνοδευόμενος από το Μπραντ Λάιτκαπ, γενικό διευθυντή της OpenAI, παρουσίασαν το Sora σε στελέχη ορισμένων από τα κορυφαία κινηματογραφικά στούντιο. Η νέα αυτή τεχνολογία κέντρισε αρχικά το ενδιαφέρον του Χόλυγουντ από τη στιγμή που η OpenAI δημοσίευσε μια σειρά βίντεο τα οποία δημιούργησε το Sora, τον περασμένο μήνα. Τα κλιπ αυτά προκάλεσαν αίσθηση στο διαδίκτυο και οδήγησαν σε μια ευρύτερη συζήτηση σχετικά με την ενδεχόμενη επίδραση του εργαλείου αυτού και της τεχνολογίας ευρύτερα, στις δημιουργικές βιομηχανίες. "Το Sora προκαλεί τεράστιο ενθουσιασμό", σχολιάζει η αναλύτρια Κλερ Έντερς. "Υπάρχει η αίσθηση πως πρόκειται να φέρει την επανάσταση στον τρόπο που δημιουργούνται οι ταινίες, περιορίζοντας το κόστος παραγωγής αλλά και την ανάγκη προσφυγής στο CGI". sora-1.mp4 Στόχος των συναντήσεων ήταν να βολιδοσκοπηθούν τα στελέχη των κινηματογραφικών στούντιο σχετικά με το πώς θα ήταν σκόπιμο να παρουσιαστεί το Sora. Ορισμένοι από τους συμμετέχοντες σχολίασαν ότι μπορούσαν να φανταστούν το πώς το Sora η ανάλογα εργαλεία τεχνητής νοημοσύνης θα περιόριζαν το κόστος παραγωγής, όμως επισήμαναν ότι η τεχνολογία χρειάζεται περαιτέρω εξέλιξη. Η προσπάθεια της OpenAI να προσεγγίσει τα στούντιο καταγράφεται σε μια ευαίσθητη περίοδο για το Χόλυγουντ. Οι περυσινές, πολύμηνες απεργίες έληξαν όταν η Αμερικανική Ένωση Σεναριογράφων και η Ένωση Ηθοποιών εξασφάλισαν την ενσωμάτωση στα συμβόλαιά τους ριζοσπαστικών ασφαλιστικών δικλείδων έναντι της τεχνητής νοημοσύνης. Φέτος, βρίσκονται ήδη σε εξέλιξη συλλογικές διαπραγματεύσεις με τη Διεθνή Συμμαχία Θεατρικών Εργαζομένων και, όπως στις προηγούμενες περιπτώσεις, το ζήτημα της τεχνητής νοημοσύνης αναμένεται να βρεθεί στο επίκεντρο. Νωρίτερα αυτή την εβδομάδα η OpenAI δημοσίευσε νέα βίντεο με χρήση του Sora, τα οποία δημιούργησαν διάφοροι καλλιτέχνες, μεταξύ των οποίων και ταινίες μικρού μήκους, καθώς και τις εντυπώσεις των δημιουργών από την όλη διαδικασία. Το μοντέλο στόχο έχει να ανταγωνιστεί διάφορες αντίστοιχες προτάσεις άλλων εταιριών, όπως αυτές των Runway, Pika και Stability AI. Τα μοντέλα που προτείνουν οι εταιρίες αυτές είναι ήδη διαθέσιμα για εμπορική χρήση. sora-2.mp4 Το Sora, όμως, δεν έχει κυκλοφορήσει ακόμη επίσημα. Η OpenAI έχει αποφύγει να δώσει συγκεκριμένη ημερομηνία διάθεσης στην αγορά, ενώ δεν έχει συζητήσει και το πλαίσιο υπό το οποίο θα είναι διαθέσιμο. Η εταιρία φέρεται να εξετάζει ακόμη το πώς θα αξιοποιήσει εμπορικά τη συγκεκριμένη τεχνολογία. Δημοσιογραφικές πηγές αναφέρουν ότι η συζήτηση εστιάζει εκτός των άλλων και στα μέτρα ασφαλείας που θα ενσωματωθούν, πριν διατεθεί το Sora ως εμπορικό προϊόν. Παράλληλα, η OpenAI συνεχίζει να βελτιώνει το σύστημα. Επί του παρόντος, το Sora περιορίζεται σε βίντεο διάρκειας κάτω του ενός λεπτού και οι δημιουργίες του έχουν ατέλειες, όπως για παράδειγμα το ότι το γυαλί αναπηδά στο πάτωμα αντί να σπάει ή ότι το μοντέλο προσθέτει περισσευούμενα μέλη σε ανθρώπους και ζώα. Ορισμένα στούντιο εμφανίστηκαν ανοιχτά στο ενδεχόμενο να χρησιμοποιήσουν το Sora για μελλοντικές κινηματογραφικές ή τηλεοπτικές παραγωγές, όμως ακόμη δεν έχουν συζητηθεί οι σχετικές άδειες και συνεργασίες. Επί του παρόντος η OpenAI παρουσιάζει το μοντέλο με "πολύ ελεγχόμενο τρόπο" σε βιομηχανίες που είναι πιθανό να επηρεαστούν αμεσότερα από την άφιξη του νέου εργαλείου. Σύμφωνα με την Έντερς, η υποδοχή από τα στελέχη των στούντιο ήταν σε γενικές γραμμές θετική, καθώς το Sora αντιμετωπίζεται ως "εργαλείο περιορισμού των εξόδων και όχι ως μηχανισμός που θα επιδρούσε στο δημιουργικό ήθος της κινηματογραφικής αφηγηματικής τέχνης". Η OpenAI δεν θέλησε να προβεί σε κάποιο σχόλιο. sora-3.mp4
Η OpenAI έχει ξεκινήσει σειρά συναντήσεων με στελέχη της αμερικανικής κινηματογραφικής βιομηχανίας, προκειμένου να παρουσιάσει το Sora, ένα εργαλείο δημιουργίας βίντεο με τη χρήση τεχνητής νοημοσύνης, επιχειρώντας παράλληλα να κατευνάσει τις ανησυχίες που θέλουν τη νέα τεχνολογία να συνιστά απειλή για το χώρο. Σύμφωνα με δημοσιογραφικές πληροφορίες, το τελευταίο διάστημα ο Σαλ Άλτμαν, διευθύνων σύμβουλος της εταιρίας, συνοδευόμενος από το Μπραντ Λάιτκαπ, γενικό διευθυντή της OpenAI, παρουσίασαν το Sora σε στελέχη ορισμένων από τα κορυφαία κινηματογραφικά στούντιο. Η νέα αυτή τεχνολογία κέντρισε αρχικά το ενδιαφέρον του Χόλυγουντ από τη στιγμή που η OpenAI δημοσίευσε μια σειρά βίντεο τα οποία δημιούργησε το Sora, τον περασμένο μήνα. Τα κλιπ αυτά προκάλεσαν αίσθηση στο διαδίκτυο και οδήγησαν σε μια ευρύτερη συζήτηση σχετικά με την ενδεχόμενη επίδραση του εργαλείου αυτού και της τεχνολογίας ευρύτερα, στις δημιουργικές βιομηχανίες. "Το Sora προκαλεί τεράστιο ενθουσιασμό", σχολιάζει η αναλύτρια Κλερ Έντερς. "Υπάρχει η αίσθηση πως πρόκειται να φέρει την επανάσταση στον τρόπο που δημιουργούνται οι ταινίες, περιορίζοντας το κόστος παραγωγής αλλά και την ανάγκη προσφυγής στο CGI". sora-1.mp4 Στόχος των συναντήσεων ήταν να βολιδοσκοπηθούν τα στελέχη των κινηματογραφικών στούντιο σχετικά με το πώς θα ήταν σκόπιμο να παρουσιαστεί το Sora. Ορισμένοι από τους συμμετέχοντες σχολίασαν ότι μπορούσαν να φανταστούν το πώς το Sora η ανάλογα εργαλεία τεχνητής νοημοσύνης θα περιόριζαν το κόστος παραγωγής, όμως επισήμαναν ότι η τεχνολογία χρειάζεται περαιτέρω εξέλιξη. Η προσπάθεια της OpenAI να προσεγγίσει τα στούντιο καταγράφεται σε μια ευαίσθητη περίοδο για το Χόλυγουντ. Οι περυσινές, πολύμηνες απεργίες έληξαν όταν η Αμερικανική Ένωση Σεναριογράφων και η Ένωση Ηθοποιών εξασφάλισαν την ενσωμάτωση στα συμβόλαιά τους ριζοσπαστικών ασφαλιστικών δικλείδων έναντι της τεχνητής νοημοσύνης. Φέτος, βρίσκονται ήδη σε εξέλιξη συλλογικές διαπραγματεύσεις με τη Διεθνή Συμμαχία Θεατρικών Εργαζομένων και, όπως στις προηγούμενες περιπτώσεις, το ζήτημα της τεχνητής νοημοσύνης αναμένεται να βρεθεί στο επίκεντρο. Νωρίτερα αυτή την εβδομάδα η OpenAI δημοσίευσε νέα βίντεο με χρήση του Sora, τα οποία δημιούργησαν διάφοροι καλλιτέχνες, μεταξύ των οποίων και ταινίες μικρού μήκους, καθώς και τις εντυπώσεις των δημιουργών από την όλη διαδικασία. Το μοντέλο στόχο έχει να ανταγωνιστεί διάφορες αντίστοιχες προτάσεις άλλων εταιριών, όπως αυτές των Runway, Pika και Stability AI. Τα μοντέλα που προτείνουν οι εταιρίες αυτές είναι ήδη διαθέσιμα για εμπορική χρήση. sora-2.mp4 Το Sora, όμως, δεν έχει κυκλοφορήσει ακόμη επίσημα. Η OpenAI έχει αποφύγει να δώσει συγκεκριμένη ημερομηνία διάθεσης στην αγορά, ενώ δεν έχει συζητήσει και το πλαίσιο υπό το οποίο θα είναι διαθέσιμο. Η εταιρία φέρεται να εξετάζει ακόμη το πώς θα αξιοποιήσει εμπορικά τη συγκεκριμένη τεχνολογία. Δημοσιογραφικές πηγές αναφέρουν ότι η συζήτηση εστιάζει εκτός των άλλων και στα μέτρα ασφαλείας που θα ενσωματωθούν, πριν διατεθεί το Sora ως εμπορικό προϊόν. Παράλληλα, η OpenAI συνεχίζει να βελτιώνει το σύστημα. Επί του παρόντος, το Sora περιορίζεται σε βίντεο διάρκειας κάτω του ενός λεπτού και οι δημιουργίες του έχουν ατέλειες, όπως για παράδειγμα το ότι το γυαλί αναπηδά στο πάτωμα αντί να σπάει ή ότι το μοντέλο προσθέτει περισσευούμενα μέλη σε ανθρώπους και ζώα. Ορισμένα στούντιο εμφανίστηκαν ανοιχτά στο ενδεχόμενο να χρησιμοποιήσουν το Sora για μελλοντικές κινηματογραφικές ή τηλεοπτικές παραγωγές, όμως ακόμη δεν έχουν συζητηθεί οι σχετικές άδειες και συνεργασίες. Επί του παρόντος η OpenAI παρουσιάζει το μοντέλο με "πολύ ελεγχόμενο τρόπο" σε βιομηχανίες που είναι πιθανό να επηρεαστούν αμεσότερα από την άφιξη του νέου εργαλείου. Σύμφωνα με την Έντερς, η υποδοχή από τα στελέχη των στούντιο ήταν σε γενικές γραμμές θετική, καθώς το Sora αντιμετωπίζεται ως "εργαλείο περιορισμού των εξόδων και όχι ως μηχανισμός που θα επιδρούσε στο δημιουργικό ήθος της κινηματογραφικής αφηγηματικής τέχνης". Η OpenAI δεν θέλησε να προβεί σε κάποιο σχόλιο. sora-3.mp4- 9 σχόλια
-
- 1
-

-
- τεχνητή νοημοσύνη
- Sora
- (και 1 περισσότερα)
-
Οι διαφορές είναι μικρές, όμως το Claude 3 επιβεβαιώνει την ανοδική τροχιά που διαγράφει εδώ και καιρό, έχοντας συγκεντρώσει το ενδιαφέρον σημαντικών επενδυτών. Η Anthropic μόλις κυκλοφόρησε νέα μοντέλα του Claude 3, με τις πρώτες δοκιμές να δείχνουν ότι αποδίδει καλύτερα σε οδηγίες για τη σύνταξη κώδικα. Αυτό επιβεβαιώνεται από τις μετρήσεις που πραγματοποιήθηκαν μέσω του benchmark που έχει αναπτύξει η Aider. Oι διαφορές είναι μικρές, όμως το Claude 3 Opus αποδίδει καλύτερα σε σχέση με όλα τα μοντέλα του GPT-4, καθιστώντας το τη δεδομένη στιγμή το καλύτερο διαθέσιμο μοντέλο για συνδυαστικό προγραμματισμό με την αρωγή της τεχνητής νοημοσύνης. Μέχρι στιγμής, οι διάφορες εκδοχές του GPT-4 κατατάσσονταν πρώτες, επομένως η έστω και οριακή επικράτηση του Claude 3 είναι μια σημαντική στιγμή, στη σχετικά σύντομη ιστορία των γλωσσικών μοντέλων τεχνητής νοημοσύνης. Εντωμεταξύ, ένα από τα μικρότερα μοντέλα της Anthropic, το Haiku, κερδίζει τις εντυπώσεις με τις επιδόσεις που καταγράφει. "Για πρώτη φορά, τα καλύτερα διαθέσιμα μοντέλα -το Opus για προηγμένες διαδικασίες, το Haiku για όσους προκρίνουν κόστος και αποδοτικότητα- προέρχονται από εταιρία που δεν είναι η OpenAI", ανέφερε ο ανεξάρτητος ερευνητής Σάιμον Γουίλισον, σε δηλώσεις του στο Ars Technica. "Αυτό είναι θετικό, καθώς όλοι ωφελούμαστε από το να υπάρχει ποικιλία προτάσεων σε αυτό το χώρο. Από την άλλη, το GPT-4 μετράει ήδη ένα χρόνο στην αγορά και χρειάστηκε αυτός ο ένας χρόνος για να πιάσει τις επιδόσεις του κάποιο άλλο μοντέλο". Τα παραπάνω στοιχεία προέρχονται από τη Chatbot Arena, την οποία διοργανώνει ο Large Model Systems Organization (LMSYS ORG), ένας ερευνητικός οργανισμός που αναλύει τα ανοιχτά μοντέλα και δημιουργήθηκε μέσα από τη συνεργασία φοιτητών και σχολών των Πανεπιστημίων της Καλιφόρνια με έδρα το Μπέρκλεϊ, του Σαν Ντιέγκο και του Κάρνεγκι Μέλον. Η Chatobot Arena είναι ένα σημαντικό εργαλείο, καθώς τόσο οι ερευνητές όσο και οι χρήστες συχνά δυσκολεύονται στην προσπάθεια μέτρησης των επιδόσεων των διαφόρων AI chatbot, με τη βαθμολόγηση των συχνά πολύ διαφορετικών επιδόσεών τους να αποδεικνύεται δύσκολη. Σημαντική παράμετρος στην όλη διαδικασία είναι και η αίσθηση που αφήνει στο χρήστη το κάθε μοντέλο, πράγμα που επίσης δύσκολα βαθμολογείται. Η βελτίωση του Claude, εντωμεταξύ, μπορεί να θορυβήσει κάπως την OpenAI όμως, όπως σχολίασε και ο Γουίλισον, η οικογένεια των μοντέλων GPT-4 (αν και έχουν βελτιωθεί αρκετές φορές στην πορεία) μετρά πάνω από ένα χρόνο στην αγορά. Αυτή τη στιγμή, η Arena περιλαμβάνει τέσσερις διαφορετικές εκδοχές του GPT-4, που αντιστοιχούν σε σημαντικές βελτιώσεις του συγκεκριμένου μεγάλου γλωσσικού μοντέλου (LLM), με τις επιμέρους εκδόσεις να παγώνουν στο χρόνο, καθώς κάθε μία έχει ένα μοναδικό τρόπο παρουσίασης αποτελεσμάτων, και ορισμένοι developers που τις χρησιμοποιούν σε συνδυασμό με το ΑΡΙ της OpenAI προκρίνουν τη σταθερότητα, έτσι ώστε να μην πάψουν να λειτουργούν οι εφαρμογές που δημιουργούν στη βάση των αποτελεσμάτων που εμφανίζει η εκάστοτε έκδοση του GPT-4. Σε κάθε περίπτωση, και παρά την παρουσία τεσσάρων εκδόσεων του GPT-4 στη σχετική λίστα, τα μοντέλα του Claude 3 κατέγραφαν συστηματικά ανοδική πορεία στις κατατάξεις, από τη στιγμή που κυκλοφόρησαν, νωρίτερα μέσα στο Μάρτιο, ενώ ιδιαίτερα σημαντική αποδεικνύεται η ευκολία με την οποία μπορεί κανείς να περάσει από τη χρήση του GPT-4 στο Claude 3, επομένως είναι αντίστοιχα ευκολότερο να απειληθεί το μερίδιο αγοράς που κατέχει το GPT-4. Ανάλογη ανοδική τροχιά καταγράφει το επίσης αξιόλογο Gemini της Google, στο χώρο των βοηθών τεχνητής νοημοσύνης. Η OpenAI, επομένως, αισθάνεται την πίεση του ανταγωνισμού, όμως παράλληλα αναπτύσσει νέα μοντέλα. Αναμένεται να διαθέσει στην αγορά ένα σημαντικό διάδοχο του GPT-4 Turbo (είτε αυτός θα ονομάζεται GPT-4.5 είτε GPT-5) κάποια στιγμή μέσα στο 2024, ενδεχομένως ακόμη και στη διάρκεια του καλοκαιριού. Είναι προφανές ότι ο χώρος των LLM θα χαρακτηρίζεται από έντονο ανταγωνισμό στο προσεχές μέλλον, πράγμα που ενδεχομένως να οδηγήσει σε ενδιαφέρουσες ανακατατάξεις στα αποτελέσματα της Chatobot Arena στους επόμενους μήνες και ακόμη παραπέρα. Διαβάστε ολόκληρο το άρθρο
-
To Claude 3 ξεπερνά σε επιδόσεις το GPT-4 σύμφωνα με νέα μέτρηση του Aider
Axlmon δημοσίευσε ένα άρθρο στο Artificial Intelligence
 Η Anthropic μόλις κυκλοφόρησε νέα μοντέλα του Claude 3, με τις πρώτες δοκιμές να δείχνουν ότι αποδίδει καλύτερα σε οδηγίες για τη σύνταξη κώδικα. Αυτό επιβεβαιώνεται από τις μετρήσεις που πραγματοποιήθηκαν μέσω του benchmark που έχει αναπτύξει η Aider. Oι διαφορές είναι μικρές, όμως το Claude 3 Opus αποδίδει καλύτερα σε σχέση με όλα τα μοντέλα του GPT-4, καθιστώντας το τη δεδομένη στιγμή το καλύτερο διαθέσιμο μοντέλο για συνδυαστικό προγραμματισμό με την αρωγή της τεχνητής νοημοσύνης. Μέχρι στιγμής, οι διάφορες εκδοχές του GPT-4 κατατάσσονταν πρώτες, επομένως η έστω και οριακή επικράτηση του Claude 3 είναι μια σημαντική στιγμή, στη σχετικά σύντομη ιστορία των γλωσσικών μοντέλων τεχνητής νοημοσύνης. Εντωμεταξύ, ένα από τα μικρότερα μοντέλα της Anthropic, το Haiku, κερδίζει τις εντυπώσεις με τις επιδόσεις που καταγράφει. "Για πρώτη φορά, τα καλύτερα διαθέσιμα μοντέλα -το Opus για προηγμένες διαδικασίες, το Haiku για όσους προκρίνουν κόστος και αποδοτικότητα- προέρχονται από εταιρία που δεν είναι η OpenAI", ανέφερε ο ανεξάρτητος ερευνητής Σάιμον Γουίλισον, σε δηλώσεις του στο Ars Technica. "Αυτό είναι θετικό, καθώς όλοι ωφελούμαστε από το να υπάρχει ποικιλία προτάσεων σε αυτό το χώρο. Από την άλλη, το GPT-4 μετράει ήδη ένα χρόνο στην αγορά και χρειάστηκε αυτός ο ένας χρόνος για να πιάσει τις επιδόσεις του κάποιο άλλο μοντέλο". Τα παραπάνω στοιχεία προέρχονται από τη Chatbot Arena, την οποία διοργανώνει ο Large Model Systems Organization (LMSYS ORG), ένας ερευνητικός οργανισμός που αναλύει τα ανοιχτά μοντέλα και δημιουργήθηκε μέσα από τη συνεργασία φοιτητών και σχολών των Πανεπιστημίων της Καλιφόρνια με έδρα το Μπέρκλεϊ, του Σαν Ντιέγκο και του Κάρνεγκι Μέλον. Η Chatobot Arena είναι ένα σημαντικό εργαλείο, καθώς τόσο οι ερευνητές όσο και οι χρήστες συχνά δυσκολεύονται στην προσπάθεια μέτρησης των επιδόσεων των διαφόρων AI chatbot, με τη βαθμολόγηση των συχνά πολύ διαφορετικών επιδόσεών τους να αποδεικνύεται δύσκολη. Σημαντική παράμετρος στην όλη διαδικασία είναι και η αίσθηση που αφήνει στο χρήστη το κάθε μοντέλο, πράγμα που επίσης δύσκολα βαθμολογείται. Η βελτίωση του Claude, εντωμεταξύ, μπορεί να θορυβήσει κάπως την OpenAI όμως, όπως σχολίασε και ο Γουίλισον, η οικογένεια των μοντέλων GPT-4 (αν και έχουν βελτιωθεί αρκετές φορές στην πορεία) μετρά πάνω από ένα χρόνο στην αγορά. Αυτή τη στιγμή, η Arena περιλαμβάνει τέσσερις διαφορετικές εκδοχές του GPT-4, που αντιστοιχούν σε σημαντικές βελτιώσεις του συγκεκριμένου μεγάλου γλωσσικού μοντέλου (LLM), με τις επιμέρους εκδόσεις να παγώνουν στο χρόνο, καθώς κάθε μία έχει ένα μοναδικό τρόπο παρουσίασης αποτελεσμάτων, και ορισμένοι developers που τις χρησιμοποιούν σε συνδυασμό με το ΑΡΙ της OpenAI προκρίνουν τη σταθερότητα, έτσι ώστε να μην πάψουν να λειτουργούν οι εφαρμογές που δημιουργούν στη βάση των αποτελεσμάτων που εμφανίζει η εκάστοτε έκδοση του GPT-4. Σε κάθε περίπτωση, και παρά την παρουσία τεσσάρων εκδόσεων του GPT-4 στη σχετική λίστα, τα μοντέλα του Claude 3 κατέγραφαν συστηματικά ανοδική πορεία στις κατατάξεις, από τη στιγμή που κυκλοφόρησαν, νωρίτερα μέσα στο Μάρτιο, ενώ ιδιαίτερα σημαντική αποδεικνύεται η ευκολία με την οποία μπορεί κανείς να περάσει από τη χρήση του GPT-4 στο Claude 3, επομένως είναι αντίστοιχα ευκολότερο να απειληθεί το μερίδιο αγοράς που κατέχει το GPT-4. Ανάλογη ανοδική τροχιά καταγράφει το επίσης αξιόλογο Gemini της Google, στο χώρο των βοηθών τεχνητής νοημοσύνης. Η OpenAI, επομένως, αισθάνεται την πίεση του ανταγωνισμού, όμως παράλληλα αναπτύσσει νέα μοντέλα. Αναμένεται να διαθέσει στην αγορά ένα σημαντικό διάδοχο του GPT-4 Turbo (είτε αυτός θα ονομάζεται GPT-4.5 είτε GPT-5) κάποια στιγμή μέσα στο 2024, ενδεχομένως ακόμη και στη διάρκεια του καλοκαιριού. Είναι προφανές ότι ο χώρος των LLM θα χαρακτηρίζεται από έντονο ανταγωνισμό στο προσεχές μέλλον, πράγμα που ενδεχομένως να οδηγήσει σε ενδιαφέρουσες ανακατατάξεις στα αποτελέσματα της Chatobot Arena στους επόμενους μήνες και ακόμη παραπέρα.
Η Anthropic μόλις κυκλοφόρησε νέα μοντέλα του Claude 3, με τις πρώτες δοκιμές να δείχνουν ότι αποδίδει καλύτερα σε οδηγίες για τη σύνταξη κώδικα. Αυτό επιβεβαιώνεται από τις μετρήσεις που πραγματοποιήθηκαν μέσω του benchmark που έχει αναπτύξει η Aider. Oι διαφορές είναι μικρές, όμως το Claude 3 Opus αποδίδει καλύτερα σε σχέση με όλα τα μοντέλα του GPT-4, καθιστώντας το τη δεδομένη στιγμή το καλύτερο διαθέσιμο μοντέλο για συνδυαστικό προγραμματισμό με την αρωγή της τεχνητής νοημοσύνης. Μέχρι στιγμής, οι διάφορες εκδοχές του GPT-4 κατατάσσονταν πρώτες, επομένως η έστω και οριακή επικράτηση του Claude 3 είναι μια σημαντική στιγμή, στη σχετικά σύντομη ιστορία των γλωσσικών μοντέλων τεχνητής νοημοσύνης. Εντωμεταξύ, ένα από τα μικρότερα μοντέλα της Anthropic, το Haiku, κερδίζει τις εντυπώσεις με τις επιδόσεις που καταγράφει. "Για πρώτη φορά, τα καλύτερα διαθέσιμα μοντέλα -το Opus για προηγμένες διαδικασίες, το Haiku για όσους προκρίνουν κόστος και αποδοτικότητα- προέρχονται από εταιρία που δεν είναι η OpenAI", ανέφερε ο ανεξάρτητος ερευνητής Σάιμον Γουίλισον, σε δηλώσεις του στο Ars Technica. "Αυτό είναι θετικό, καθώς όλοι ωφελούμαστε από το να υπάρχει ποικιλία προτάσεων σε αυτό το χώρο. Από την άλλη, το GPT-4 μετράει ήδη ένα χρόνο στην αγορά και χρειάστηκε αυτός ο ένας χρόνος για να πιάσει τις επιδόσεις του κάποιο άλλο μοντέλο". Τα παραπάνω στοιχεία προέρχονται από τη Chatbot Arena, την οποία διοργανώνει ο Large Model Systems Organization (LMSYS ORG), ένας ερευνητικός οργανισμός που αναλύει τα ανοιχτά μοντέλα και δημιουργήθηκε μέσα από τη συνεργασία φοιτητών και σχολών των Πανεπιστημίων της Καλιφόρνια με έδρα το Μπέρκλεϊ, του Σαν Ντιέγκο και του Κάρνεγκι Μέλον. Η Chatobot Arena είναι ένα σημαντικό εργαλείο, καθώς τόσο οι ερευνητές όσο και οι χρήστες συχνά δυσκολεύονται στην προσπάθεια μέτρησης των επιδόσεων των διαφόρων AI chatbot, με τη βαθμολόγηση των συχνά πολύ διαφορετικών επιδόσεών τους να αποδεικνύεται δύσκολη. Σημαντική παράμετρος στην όλη διαδικασία είναι και η αίσθηση που αφήνει στο χρήστη το κάθε μοντέλο, πράγμα που επίσης δύσκολα βαθμολογείται. Η βελτίωση του Claude, εντωμεταξύ, μπορεί να θορυβήσει κάπως την OpenAI όμως, όπως σχολίασε και ο Γουίλισον, η οικογένεια των μοντέλων GPT-4 (αν και έχουν βελτιωθεί αρκετές φορές στην πορεία) μετρά πάνω από ένα χρόνο στην αγορά. Αυτή τη στιγμή, η Arena περιλαμβάνει τέσσερις διαφορετικές εκδοχές του GPT-4, που αντιστοιχούν σε σημαντικές βελτιώσεις του συγκεκριμένου μεγάλου γλωσσικού μοντέλου (LLM), με τις επιμέρους εκδόσεις να παγώνουν στο χρόνο, καθώς κάθε μία έχει ένα μοναδικό τρόπο παρουσίασης αποτελεσμάτων, και ορισμένοι developers που τις χρησιμοποιούν σε συνδυασμό με το ΑΡΙ της OpenAI προκρίνουν τη σταθερότητα, έτσι ώστε να μην πάψουν να λειτουργούν οι εφαρμογές που δημιουργούν στη βάση των αποτελεσμάτων που εμφανίζει η εκάστοτε έκδοση του GPT-4. Σε κάθε περίπτωση, και παρά την παρουσία τεσσάρων εκδόσεων του GPT-4 στη σχετική λίστα, τα μοντέλα του Claude 3 κατέγραφαν συστηματικά ανοδική πορεία στις κατατάξεις, από τη στιγμή που κυκλοφόρησαν, νωρίτερα μέσα στο Μάρτιο, ενώ ιδιαίτερα σημαντική αποδεικνύεται η ευκολία με την οποία μπορεί κανείς να περάσει από τη χρήση του GPT-4 στο Claude 3, επομένως είναι αντίστοιχα ευκολότερο να απειληθεί το μερίδιο αγοράς που κατέχει το GPT-4. Ανάλογη ανοδική τροχιά καταγράφει το επίσης αξιόλογο Gemini της Google, στο χώρο των βοηθών τεχνητής νοημοσύνης. Η OpenAI, επομένως, αισθάνεται την πίεση του ανταγωνισμού, όμως παράλληλα αναπτύσσει νέα μοντέλα. Αναμένεται να διαθέσει στην αγορά ένα σημαντικό διάδοχο του GPT-4 Turbo (είτε αυτός θα ονομάζεται GPT-4.5 είτε GPT-5) κάποια στιγμή μέσα στο 2024, ενδεχομένως ακόμη και στη διάρκεια του καλοκαιριού. Είναι προφανές ότι ο χώρος των LLM θα χαρακτηρίζεται από έντονο ανταγωνισμό στο προσεχές μέλλον, πράγμα που ενδεχομένως να οδηγήσει σε ενδιαφέρουσες ανακατατάξεις στα αποτελέσματα της Chatobot Arena στους επόμενους μήνες και ακόμη παραπέρα. -
 Η Microsoft προχώρησε στην πρόσληψη ενός εκ των συνιδρυτών του DeepMind, του Μουσταφά Σουλεϊμάν. Σε ανάρτησή του στο Χ, ο ίδιος ο Σουλεϊμάν ανακοίνωσε ότι εντάσσεται στο στελεχιακό δυναμικό της Microsoft, ως επικεφαλής μιας νέας ομάδας που θα αναλάβει τα προϊόντα τεχνητής νοημοσύνης τα οποία απευθύνονται στους καταναλωτές, μεταξύ των οποίων συγκαταλέγεται το Copilot, το Bing και το Edge. Ο Σουλεϊμάν θα αναλάβει επίσης χρέη εκτελεστικού αντιπροέδρου του τομέα τεχνητής νοημοσύνης της Microsoft, ενώ θα συμμετέχει και στην ομάδα των κορυφαίων στελεχών της εταιρίας που αναφέρεται απευθείας στο Σάτια Ναντέλα, διευθύνοντα σύμβουλο της εταιρίας. Ο Σουλεϊμάν υπήρξε εξ των συνιδρυτών του εργαστηρίου τεχνητής νοημοσύνης DeepMind το 2010, το οποίο εξαγόρασε τέσσερα χρόνια αργότερα η Google. Το DeepMind παραμένει στην πρωτοπορία των εξελίξεων στον τομέα της τεχνητής νοημοσύνης, εντός της Google. Ο ίδιος ο Σουλεϊμάν, όμως, έχει πάψει εδώ και χρόνια να συμμετέχει στην προσπάθεια. Τέθηκε σε αργία το 2019, λόγω της αμφιλεγόμενης κατάστασης που είχε δημιουργηθεί σε σχέση με ορισμένα προγράμματα των οποίων ήταν επικεφαλής, σύμφωνα με το τότε ρεπορτάζ του Bloomberg. Αργότερα, η Wall Street Journal ανέφερε ότι Google και DeepMind είχαν ξεκινήσει έρευνα γύρω από το Σουλεϊμάν, λόγω καταγγελιών για επιθετική συμπεριφορά έναντι συνεργατών του. Μετά την υποχρεωτική άδεια που έλαβε ο Σουλεϊμάν από το DeepMind, η Google ανακοίνωσε ότι τον είχε προσλάβει ως αντιπρόεδρο του τομέα διαχείρισης προϊόντων τεχνητής νοημοσύνης και πολιτικής τεχνητής νοημοσύνης. Ο Σουλεϊμάν αποχώρησε από τη Google το 2022, προκειμένου να συμμετάσχει στην ίδρυση της εταιρίας Inflection AI. Εκτός της πρόσληψης του Σουλεϊμάν, η Microsoft εντάσσει στο δυναμικό της και ορισμένους από τους εργαζομένους στην Inflection AI, ανάμεσά τους έναν ακόμη από τους συνιδρυτές της εταιρίας, τον Καρέν Σιμονγιάν, ο οποίος θα αναλάβει χρέη επικεφαλής επιστημονικού συμβούλου της ομάδας καταναλωτικών προϊόντων τεχνητής νοημοσύνης. Ο Κέβιν Σκοτ θα παραμείνει στη θέση του ως επικεφαλής του τομέα τεχνολογίας και εκτελεστικός αντιπρόεδρος του τομέα τεχνητής νοημοσύνης στη Microsoft. "Γνωρίζω το Μουσταφά εδώ και αρκετά χρόνια και τρέφω μεγάλο σεβασμό απέναντί του, ως ιδρυτή τόσο του DeepMind όσο και της Inflection, αλλά και ως οραματιστή, δημιουργού προϊόντος και συντονιστή πρωτοποριακών ομάδων που θέτουν τολμηρούς στόχους", αναφέρει ο Νταντέλα σε υπόμνημα προς τους εργαζομένους που έδωσε στη δημοσιότητα η Microsoft. "Έχουμε μια πραγματική ευκαιρία να δημιουργήσουμε τεχνολογία που κάποτε θεωρούταν ανέφικτη, τεχνολογία που ανταποκρίνεται στην αποστολή μας να διασφαλίσουμε ότι τα οφέλη της τεχνητής νοημοσύνης θα φτάσουν σε κάθε άνθρωπο και οργανισμό στον πλανήτη, με ασφάλεια και υπευθυνότητα". Η Microsoft έχει επενδύσει τεράστια κεφάλαια στη συνεργασία της με την OpenAI και πρόσφατα υπέγραψε συμφωνία με τη Mistral, που επίσης ασχολείται με την ανάπτυξη της τεχνητής νοημοσύνης. Η συγκρότηση μιας νέας ομάδας πάνω στο αντικείμενο αυτό δεν σημαίνει ότι η Microsoft έχει ξεχάσει αυτές τις συνεργασίες. Όπως αναφέρει η εταιρία, "θα συνεχιστεί η δημιουργία υποδομών τεχνητής νοημοσύνης, συμπεριλαμβανομένων ειδικά σχεδιασμένων συστημάτων με στόχο την υποστήριξη του οδικού χάρτη της OpenAI για τα θεμελιώδη μοντέλα", καθώς και "τη δημιουργία προϊόντων που βασίζονται στα θεμελιώδη μοντέλα τους". Μετά την κυκλοφορία του Bing Chat (νυν Copilot) τον περασμένο χρόνο, η Microsoft έχει ενσωματώσει αυτό το βοηθό τεχνητής νοημοσύνης στα προϊόντα της σουίτας Office, στα Windows 11 και το Edge. Υπενθυμίζεται πως η Microsoft πρόκειται να οργανώσει ειδική εκδήλωση με κεντρικό άξονα την τεχνητή νοημοσύνη, ενόψει της έναρξης του συνεδρίου Build, το Μάιο, όπου είναι πιθανό να προχωρήσει σε νέες ανακοινώσεις σχετικά με τις φιλοδοξίες της στον τομέα τεχνητής νοημοσύνης για τα Windows και τις συσκευές Surface.
Η Microsoft προχώρησε στην πρόσληψη ενός εκ των συνιδρυτών του DeepMind, του Μουσταφά Σουλεϊμάν. Σε ανάρτησή του στο Χ, ο ίδιος ο Σουλεϊμάν ανακοίνωσε ότι εντάσσεται στο στελεχιακό δυναμικό της Microsoft, ως επικεφαλής μιας νέας ομάδας που θα αναλάβει τα προϊόντα τεχνητής νοημοσύνης τα οποία απευθύνονται στους καταναλωτές, μεταξύ των οποίων συγκαταλέγεται το Copilot, το Bing και το Edge. Ο Σουλεϊμάν θα αναλάβει επίσης χρέη εκτελεστικού αντιπροέδρου του τομέα τεχνητής νοημοσύνης της Microsoft, ενώ θα συμμετέχει και στην ομάδα των κορυφαίων στελεχών της εταιρίας που αναφέρεται απευθείας στο Σάτια Ναντέλα, διευθύνοντα σύμβουλο της εταιρίας. Ο Σουλεϊμάν υπήρξε εξ των συνιδρυτών του εργαστηρίου τεχνητής νοημοσύνης DeepMind το 2010, το οποίο εξαγόρασε τέσσερα χρόνια αργότερα η Google. Το DeepMind παραμένει στην πρωτοπορία των εξελίξεων στον τομέα της τεχνητής νοημοσύνης, εντός της Google. Ο ίδιος ο Σουλεϊμάν, όμως, έχει πάψει εδώ και χρόνια να συμμετέχει στην προσπάθεια. Τέθηκε σε αργία το 2019, λόγω της αμφιλεγόμενης κατάστασης που είχε δημιουργηθεί σε σχέση με ορισμένα προγράμματα των οποίων ήταν επικεφαλής, σύμφωνα με το τότε ρεπορτάζ του Bloomberg. Αργότερα, η Wall Street Journal ανέφερε ότι Google και DeepMind είχαν ξεκινήσει έρευνα γύρω από το Σουλεϊμάν, λόγω καταγγελιών για επιθετική συμπεριφορά έναντι συνεργατών του. Μετά την υποχρεωτική άδεια που έλαβε ο Σουλεϊμάν από το DeepMind, η Google ανακοίνωσε ότι τον είχε προσλάβει ως αντιπρόεδρο του τομέα διαχείρισης προϊόντων τεχνητής νοημοσύνης και πολιτικής τεχνητής νοημοσύνης. Ο Σουλεϊμάν αποχώρησε από τη Google το 2022, προκειμένου να συμμετάσχει στην ίδρυση της εταιρίας Inflection AI. Εκτός της πρόσληψης του Σουλεϊμάν, η Microsoft εντάσσει στο δυναμικό της και ορισμένους από τους εργαζομένους στην Inflection AI, ανάμεσά τους έναν ακόμη από τους συνιδρυτές της εταιρίας, τον Καρέν Σιμονγιάν, ο οποίος θα αναλάβει χρέη επικεφαλής επιστημονικού συμβούλου της ομάδας καταναλωτικών προϊόντων τεχνητής νοημοσύνης. Ο Κέβιν Σκοτ θα παραμείνει στη θέση του ως επικεφαλής του τομέα τεχνολογίας και εκτελεστικός αντιπρόεδρος του τομέα τεχνητής νοημοσύνης στη Microsoft. "Γνωρίζω το Μουσταφά εδώ και αρκετά χρόνια και τρέφω μεγάλο σεβασμό απέναντί του, ως ιδρυτή τόσο του DeepMind όσο και της Inflection, αλλά και ως οραματιστή, δημιουργού προϊόντος και συντονιστή πρωτοποριακών ομάδων που θέτουν τολμηρούς στόχους", αναφέρει ο Νταντέλα σε υπόμνημα προς τους εργαζομένους που έδωσε στη δημοσιότητα η Microsoft. "Έχουμε μια πραγματική ευκαιρία να δημιουργήσουμε τεχνολογία που κάποτε θεωρούταν ανέφικτη, τεχνολογία που ανταποκρίνεται στην αποστολή μας να διασφαλίσουμε ότι τα οφέλη της τεχνητής νοημοσύνης θα φτάσουν σε κάθε άνθρωπο και οργανισμό στον πλανήτη, με ασφάλεια και υπευθυνότητα". Η Microsoft έχει επενδύσει τεράστια κεφάλαια στη συνεργασία της με την OpenAI και πρόσφατα υπέγραψε συμφωνία με τη Mistral, που επίσης ασχολείται με την ανάπτυξη της τεχνητής νοημοσύνης. Η συγκρότηση μιας νέας ομάδας πάνω στο αντικείμενο αυτό δεν σημαίνει ότι η Microsoft έχει ξεχάσει αυτές τις συνεργασίες. Όπως αναφέρει η εταιρία, "θα συνεχιστεί η δημιουργία υποδομών τεχνητής νοημοσύνης, συμπεριλαμβανομένων ειδικά σχεδιασμένων συστημάτων με στόχο την υποστήριξη του οδικού χάρτη της OpenAI για τα θεμελιώδη μοντέλα", καθώς και "τη δημιουργία προϊόντων που βασίζονται στα θεμελιώδη μοντέλα τους". Μετά την κυκλοφορία του Bing Chat (νυν Copilot) τον περασμένο χρόνο, η Microsoft έχει ενσωματώσει αυτό το βοηθό τεχνητής νοημοσύνης στα προϊόντα της σουίτας Office, στα Windows 11 και το Edge. Υπενθυμίζεται πως η Microsoft πρόκειται να οργανώσει ειδική εκδήλωση με κεντρικό άξονα την τεχνητή νοημοσύνη, ενόψει της έναρξης του συνεδρίου Build, το Μάιο, όπου είναι πιθανό να προχωρήσει σε νέες ανακοινώσεις σχετικά με τις φιλοδοξίες της στον τομέα τεχνητής νοημοσύνης για τα Windows και τις συσκευές Surface. -
Ο Μουσταφά Σουλεϊμάν θα εποπτεύει την ανάπτυξη των καταναλωτικών προϊόντων τεχνητής νοημοσύνης της Microsoft, μεταξύ των οποίων τα Copilot, Bing και Edge. Η Microsoft προχώρησε στην πρόσληψη ενός εκ των συνιδρυτών του DeepMind, του Μουσταφά Σουλεϊμάν. Σε ανάρτησή του στο Χ, ο ίδιος ο Σουλεϊμάν ανακοίνωσε ότι εντάσσεται στο στελεχιακό δυναμικό της Microsoft, ως επικεφαλής μιας νέας ομάδας που θα αναλάβει τα προϊόντα τεχνητής νοημοσύνης τα οποία απευθύνονται στους καταναλωτές, μεταξύ των οποίων συγκαταλέγεται το Copilot, το Bing και το Edge. Ο Σουλεϊμάν θα αναλάβει επίσης χρέη εκτελεστικού αντιπροέδρου του τομέα τεχνητής νοημοσύνης της Microsoft, ενώ θα συμμετέχει και στην ομάδα των κορυφαίων στελεχών της εταιρίας που αναφέρεται απευθείας στο Σάτια Ναντέλα, διευθύνοντα σύμβουλο της εταιρίας. Ο Σουλεϊμάν υπήρξε εξ των συνιδρυτών του εργαστηρίου τεχνητής νοημοσύνης DeepMind το 2010, το οποίο εξαγόρασε τέσσερα χρόνια αργότερα η Google. Το DeepMind παραμένει στην πρωτοπορία των εξελίξεων στον τομέα της τεχνητής νοημοσύνης, εντός της Google. Ο ίδιος ο Σουλεϊμάν, όμως, έχει πάψει εδώ και χρόνια να συμμετέχει στην προσπάθεια. Τέθηκε σε αργία το 2019, λόγω της αμφιλεγόμενης κατάστασης που είχε δημιουργηθεί σε σχέση με ορισμένα προγράμματα των οποίων ήταν επικεφαλής, σύμφωνα με το τότε ρεπορτάζ του Bloomberg. Αργότερα, η Wall Street Journal ανέφερε ότι Google και DeepMind είχαν ξεκινήσει έρευνα γύρω από το Σουλεϊμάν, λόγω καταγγελιών για επιθετική συμπεριφορά έναντι συνεργατών του. Μετά την υποχρεωτική άδεια που έλαβε ο Σουλεϊμάν από το DeepMind, η Google ανακοίνωσε ότι τον είχε προσλάβει ως αντιπρόεδρο του τομέα διαχείρισης προϊόντων τεχνητής νοημοσύνης και πολιτικής τεχνητής νοημοσύνης. Ο Σουλεϊμάν αποχώρησε από τη Google το 2022, προκειμένου να συμμετάσχει στην ίδρυση της εταιρίας Inflection AI. Εκτός της πρόσληψης του Σουλεϊμάν, η Microsoft εντάσσει στο δυναμικό της και ορισμένους από τους εργαζομένους στην Inflection AI, ανάμεσά τους έναν ακόμη από τους συνιδρυτές της εταιρίας, τον Καρέν Σιμονγιάν, ο οποίος θα αναλάβει χρέη επικεφαλής επιστημονικού συμβούλου της ομάδας καταναλωτικών προϊόντων τεχνητής νοημοσύνης. Ο Κέβιν Σκοτ θα παραμείνει στη θέση του ως επικεφαλής του τομέα τεχνολογίας και εκτελεστικός αντιπρόεδρος του τομέα τεχνητής νοημοσύνης στη Microsoft. "Γνωρίζω το Μουσταφά εδώ και αρκετά χρόνια και τρέφω μεγάλο σεβασμό απέναντί του, ως ιδρυτή τόσο του DeepMind όσο και της Inflection, αλλά και ως οραματιστή, δημιουργού προϊόντος και συντονιστή πρωτοποριακών ομάδων που θέτουν τολμηρούς στόχους", αναφέρει ο Νταντέλα σε υπόμνημα προς τους εργαζομένους που έδωσε στη δημοσιότητα η Microsoft. "Έχουμε μια πραγματική ευκαιρία να δημιουργήσουμε τεχνολογία που κάποτε θεωρούταν ανέφικτη, τεχνολογία που ανταποκρίνεται στην αποστολή μας να διασφαλίσουμε ότι τα οφέλη της τεχνητής νοημοσύνης θα φτάσουν σε κάθε άνθρωπο και οργανισμό στον πλανήτη, με ασφάλεια και υπευθυνότητα". Η Microsoft έχει επενδύσει τεράστια κεφάλαια στη συνεργασία της με την OpenAI και πρόσφατα υπέγραψε συμφωνία με τη Mistral, που επίσης ασχολείται με την ανάπτυξη της τεχνητής νοημοσύνης. Η συγκρότηση μιας νέας ομάδας πάνω στο αντικείμενο αυτό δεν σημαίνει ότι η Microsoft έχει ξεχάσει αυτές τις συνεργασίες. Όπως αναφέρει η εταιρία, "θα συνεχιστεί η δημιουργία υποδομών τεχνητής νοημοσύνης, συμπεριλαμβανομένων ειδικά σχεδιασμένων συστημάτων με στόχο την υποστήριξη του οδικού χάρτη της OpenAI για τα θεμελιώδη μοντέλα", καθώς και "τη δημιουργία προϊόντων που βασίζονται στα θεμελιώδη μοντέλα τους". Μετά την κυκλοφορία του Bing Chat (νυν Copilot) τον περασμένο χρόνο, η Microsoft έχει ενσωματώσει αυτό το βοηθό τεχνητής νοημοσύνης στα προϊόντα της σουίτας Office, στα Windows 11 και το Edge. Υπενθυμίζεται πως η Microsoft πρόκειται να οργανώσει ειδική εκδήλωση με κεντρικό άξονα την τεχνητή νοημοσύνη, ενόψει της έναρξης του συνεδρίου Build, το Μάιο, όπου είναι πιθανό να προχωρήσει σε νέες ανακοινώσεις σχετικά με τις φιλοδοξίες της στον τομέα τεχνητής νοημοσύνης για τα Windows και τις συσκευές Surface. Διαβάστε ολόκληρο το άρθρο
-
H AMD ανακοίνωσε το δικό της LLM-powered AI chatbot που βασίζεται στις δυνατότητες του GPT της OpenAI και «τρέχει» σε τοπικό επίπεδο σε υπολογιστές που διαθέτουν επεξεργαστή με δυνατότητες AMD Ryzen AI ή κάρτα γραφικών Radeon RX 7000-series. Το νέο AI chatbot της AMD μπορεί και «τρέχει» σε διάφορες πλατφόρμες Ryzen AI, συμπεριλαμβανομένων των Ryzen 7000 και 8000-series APUs που ενσωματώνουν μονάδα νευρωνικής επεξεργασίας (NPU) αρχιτεκτονικής XDNA καθώς και σε κάρτες γραφικών Radeon RX 7000-series με πυρήνες επιτάχυνσης AI. Η εταιρεία ανάρτησε στο blog της έναν οδηγό που μπορεί να σας βοηθήσει με την εγκατάσταση και τις ρυθμίσεις που απαιτούνται για να λειτουργήσετε σε τοπικό επίπεδο το δικό σας AI chatbot που τροφοδοτείται από GPT-based LLMs (Large Language Models). Αν διαθέτετε υπολογιστή με επεξεργαστή ή μονάδα επιταχυνόμενης επεξεργασίας (APU), χρειάζεστε ένα τυπικό αντίγραφο του LM Studio για Windows ενώ αν διαθέτετε κάρτα γραφικών Radeon RX 7000-series αρχιτεκτονικής RDNA3, τότε χρειάζεστε το ROCm (Technical Preview). Η AMD δεν είναι η πρώτη εταιρεία που κάνει κάτι τέτοιο, αλλά στην ουσία ακολουθεί την NVIDIA που πρώτη ανακοίνωσε το «Chat with RTX», ένα AI chatbot που για να «τρέξει» απαιτεί κάρτα γραφικών GeForce RTX 40 ή RTX 30-series. Την επιτάχυνση του, αναλαμβάνει το σετ χαρακτηριστικών TensorRT-LLM και προσφέρει ταχύτατα αποτελέσματα δημιουργικής ή παραγωγικής Τεχνητής Νοημοσύνης που βασίζονται σε τοπικά σύνολα δεδομένων. Μετά λοιπόν την ανακοίνωση της NVIDIA, η AMD έκανε γνωστή τη διάθεση της δικής της εκδοχής για ένα AI chatbot που λειτουργεί σε τοπικό επίπεδο. Εφόσον λοιπόν διαθέτετε υπολογιστή με hardware που πληροί τις προδιαγραφές, μπορείτε να ανατρέξετε στην ιστοσελίδα της AMD για να δείτε πως να το διαμορφώσετε-ρυθμίσετε. Διαβάστε ολόκληρο το άρθρο
-
 Το νέο AI chatbot της AMD μπορεί και «τρέχει» σε διάφορες πλατφόρμες Ryzen AI, συμπεριλαμβανομένων των Ryzen 7000 και 8000-series APUs που ενσωματώνουν μονάδα νευρωνικής επεξεργασίας (NPU) αρχιτεκτονικής XDNA καθώς και σε κάρτες γραφικών Radeon RX 7000-series με πυρήνες επιτάχυνσης AI. Η εταιρεία ανάρτησε στο blog της έναν οδηγό που μπορεί να σας βοηθήσει με την εγκατάσταση και τις ρυθμίσεις που απαιτούνται για να λειτουργήσετε σε τοπικό επίπεδο το δικό σας AI chatbot που τροφοδοτείται από GPT-based LLMs (Large Language Models). Αν διαθέτετε υπολογιστή με επεξεργαστή ή μονάδα επιταχυνόμενης επεξεργασίας (APU), χρειάζεστε ένα τυπικό αντίγραφο του LM Studio για Windows ενώ αν διαθέτετε κάρτα γραφικών Radeon RX 7000-series αρχιτεκτονικής RDNA3, τότε χρειάζεστε το ROCm (Technical Preview). Η AMD δεν είναι η πρώτη εταιρεία που κάνει κάτι τέτοιο, αλλά στην ουσία ακολουθεί την NVIDIA που πρώτη ανακοίνωσε το «Chat with RTX», ένα AI chatbot που για να «τρέξει» απαιτεί κάρτα γραφικών GeForce RTX 40 ή RTX 30-series. Την επιτάχυνση του, αναλαμβάνει το σετ χαρακτηριστικών TensorRT-LLM και προσφέρει ταχύτατα αποτελέσματα δημιουργικής ή παραγωγικής Τεχνητής Νοημοσύνης που βασίζονται σε τοπικά σύνολα δεδομένων. Μετά λοιπόν την ανακοίνωση της NVIDIA, η AMD έκανε γνωστή τη διάθεση της δικής της εκδοχής για ένα AI chatbot που λειτουργεί σε τοπικό επίπεδο. Εφόσον λοιπόν διαθέτετε υπολογιστή με hardware που πληροί τις προδιαγραφές, μπορείτε να ανατρέξετε στην ιστοσελίδα της AMD για να δείτε πως να το διαμορφώσετε-ρυθμίσετε.
Το νέο AI chatbot της AMD μπορεί και «τρέχει» σε διάφορες πλατφόρμες Ryzen AI, συμπεριλαμβανομένων των Ryzen 7000 και 8000-series APUs που ενσωματώνουν μονάδα νευρωνικής επεξεργασίας (NPU) αρχιτεκτονικής XDNA καθώς και σε κάρτες γραφικών Radeon RX 7000-series με πυρήνες επιτάχυνσης AI. Η εταιρεία ανάρτησε στο blog της έναν οδηγό που μπορεί να σας βοηθήσει με την εγκατάσταση και τις ρυθμίσεις που απαιτούνται για να λειτουργήσετε σε τοπικό επίπεδο το δικό σας AI chatbot που τροφοδοτείται από GPT-based LLMs (Large Language Models). Αν διαθέτετε υπολογιστή με επεξεργαστή ή μονάδα επιταχυνόμενης επεξεργασίας (APU), χρειάζεστε ένα τυπικό αντίγραφο του LM Studio για Windows ενώ αν διαθέτετε κάρτα γραφικών Radeon RX 7000-series αρχιτεκτονικής RDNA3, τότε χρειάζεστε το ROCm (Technical Preview). Η AMD δεν είναι η πρώτη εταιρεία που κάνει κάτι τέτοιο, αλλά στην ουσία ακολουθεί την NVIDIA που πρώτη ανακοίνωσε το «Chat with RTX», ένα AI chatbot που για να «τρέξει» απαιτεί κάρτα γραφικών GeForce RTX 40 ή RTX 30-series. Την επιτάχυνση του, αναλαμβάνει το σετ χαρακτηριστικών TensorRT-LLM και προσφέρει ταχύτατα αποτελέσματα δημιουργικής ή παραγωγικής Τεχνητής Νοημοσύνης που βασίζονται σε τοπικά σύνολα δεδομένων. Μετά λοιπόν την ανακοίνωση της NVIDIA, η AMD έκανε γνωστή τη διάθεση της δικής της εκδοχής για ένα AI chatbot που λειτουργεί σε τοπικό επίπεδο. Εφόσον λοιπόν διαθέτετε υπολογιστή με hardware που πληροί τις προδιαγραφές, μπορείτε να ανατρέξετε στην ιστοσελίδα της AMD για να δείτε πως να το διαμορφώσετε-ρυθμίσετε. -
To μέτρο αφορά εκλογικές αναμετρήσεις που είναι προγραμματισμένες για το 2024 Η Google αποφάσισε να περιορίσει το Gemini ώστε να μην απαντά σε ερωτήσεις που αφορούν εκλογές οι οποίες πρόκειται να πραγματοποιηθούν μέσα στη χρονιά που διανύουμε, όπως ανακοίνωσε η εταιρία την Τρίτη, καθώς φαίνεται πως θέλει να αποφύγει τυχόν αστοχίες στην εφαρμογή του μοντέλου τεχνητής νοημοσύνης. Η εξέλιξη αυτή καταγράφεται σε μια περίοδο κατά την οποία οι εξελίξεις στον τομέα της δημιουργικής τεχνητής νοημοσύνης, συμπεριλαμβανομένης της δημιουργίας εικόνων και βίντεο, έχουν προκαλέσει ανησυχίες γύρω από το ενδεχόμενο εκμετάλλευσης της τεχνολογίας για την παραπληροφόρηση και τη διασπορά ψευδών ειδήσεων, περίπτωση που ώθησε ήδη ορισμένες κυβερνήσεις να επιβάλουν ρυθμιστικό πλαίσιο στη χρήση της τεχνολογίας αυτής. Όταν δέχεται ερωτήσεις σχετικά με εκλογές όπως η επικείμενη αναμέτρηση μεταξύ του Τζο Μπάιντεν και του Ντόναλντ Τραμπ για την προεδρία των Ηνωμένων Πολιτειών, το Gemini απαντά με τη φράση "Ακόμη μαθαίνω πώς να απαντώ σε αυτή την ερώτηση. Στο μεταξύ, δοκίμασε το Google Search". Η Google είχε ανακοινώσει ήδη από το Δεκέμβριο την πρόθεσή της να μην εμπλέξει το Gemini στις αμερικανικές εκλογές, λέγοντας πως οι περιορισμοί αυτοί θα επιβάλλονταν εγκαίρως. "Ενόψει των πολλών εκλογικών αναμετρήσεων σε ολόκληρο τον κόσμο μέσα στο 2024 και εντελώς προληπτικά, προχωράμε στον περιορισμό των κατηγοριών ερωτήσεων σχετικών με εκλογές στις οποίες θα απαντά το Gemini", ανέφερε εκπρόσωπος της εταιρίας. Πέρα από τις Ηνωμένες Πολιτείες, εθνικές εκλογές πρόκειται να πραγματοποιηθούν σε αρκετές μεγάλες χώρες, συμπεριλαμβανομένης της Νότιας Αφρικής αλλά και της Ινδίας, της πολυπληθέστερης δημοκρατίας στον πλανήτη. Η Ινδία είχε ήδη ζητήσει από τεχνολογικές εταιρίες να λάβουν την έγκριση της κυβέρνησης πριν προχωρήσουν στη δημόσια διάθεση εργαλείων τεχνητής νοημοσύνης τα οποία χαρακτήρισε "αναξιόπιστα" ή σε στάδιο δοκιμών, καθώς και να ενημερώνουν τους χρήστες για το ενδεχόμενο να λάβουν λανθασμένες απαντήσεις. Τα προϊόντα τεχνητής νοημοσύνης της Google έχουν τεθεί ήδη στο μικροσκόπιο καθώς εντοπίστηκαν ανακρίβειες σε ορισμένες απεικονίσεις ιστορικών προσώπων που παρήγαγε το Gemini, υποχρεώνοντας την εταιρία στα τέλη Φεβρουαρίου να προβεί στην αναστολή της λειτουργίας που επέτρεπε στο chatbot να δημιουργεί εικόνες. Διαβάστε ολόκληρο το άρθρο
-
 Στο πλαίσιο του ετήσιου συνεδρίου της Nvidia που απευθύνεται στους developers θα έχουμε την ευκαιρία να δούμε το πώς σχεδιάζει να κινηθεί στο άμεσο μέλλον η εταιρία που αυτή τη στιγμή πρωταγωνιστεί στις εξελίξεις στον τομέα της τεχνητής νοημοσύνης. Το συνέδριο θα είναι το πρώτο που θα πραγματοποιηθεί δια ζώσης μετά την πανδημία. Η Nvidia αναμένει τη συμμετοχή 16.000 ανθρώπων στην εκδήλωση, αριθμός περίπου διπλάσιος σε σχέση με εκείνους είχαν αυτοπρόσωπη παρουσία στην εκδήλωση του 2019. Στα τέλη Φεβρουαρίου, η χρηματιστηριακή αποτίμηση της Nvidia ξεπέρασε τα 2 τρισεκατομμύρια δολάρια και πλέον απέχει "μόλις" 400 δισεκατομμύρια δολάρια από το να ξεπεράσει την Apple ως η εταιρία με τη δεύτερη υψηλότερη κεφαλαιοποίηση στο αμερικανικό χρηματιστήριο, πίσω από τη Microsoft, που αναμένεται να διατηρήσει την πρωτοκαθεδρία της. Αναλυτές εκτιμούν ότι τα έσοδα της Nvidia θα καταγράψουν φέτος θεματική αύξηση, κατά 81%, φτάνοντας στα 110 δισεκατομμύρια δολάρια, καθώς οι εταιρίες του χώρου αγοράζουν κατά δεκάδες χιλιάδες τα κορυφαίας τεχνολογίας chip της εταιρίας, προκειμένου να βασίσουν σε αυτά chatbots, προγράμματα δημιουργίας εικόνων και άλλα συστήματα τεχνητής νοημοσύνης. Οι πωλήσεις αυτές είναι διπλάσιες εκείνων που οι αναλυτές προβλέπουν για την Intel, την εταιρία που κυριάρχησε στην εποχή της ραγδαίας ενίσχυσης των προσωπικών υπολογιστών. Το ερώτημα είναι κατά πόσο η Nvidia μπορεί να διατηρήσει το πρόσφατο, εντυπωσιακό προβάδισμά της στον τομέα της τεχνητής νοημοσύνης και να το μεταφράσει σε μακροπρόθεσμα κυρίαρχη θέση σε αυτή τη νέα εποχή της τεχνολογίας. Στο επίκεντρο της προσπάθειας αυτής θα βρεθεί ο νέος κορυφαίος AI επεξεργαστής της εταιρίας, ο οποίος εκτιμάται ότι θα παρουσιαστεί με την επωνυμία Β100. Το chip θα διαδραματίζει κεντρικό ρόλο στα συστήματα τεχνητής νοημοσύνης που διαθέτει στην αγορά η Nvidia και πιθανότατα θα αρχίσει να αποστέλλεται στους πελάτες της εταιρίας μέσα στο 2024. Η ζήτηση για τα προϊόντα της Nvidia υπερβαίνει εδώ και καιρό την προσφορά, καθώς υπάρχουν περιπτώσεις ενδιαφερόμενων στον τομέα της ανάπτυξης λογισμικού που περιμένουν επί μήνες για μια ευκαιρία να χρησιμοποιήσουν υπολογιστές βελτιστοποιημένους για χρήση τεχνητής νοημοσύνης. Είναι απίθανο να ανακοινώσει η Nvidia συγκεκριμένες τιμές στην εκδήλωση της ερχόμενης εβδομάδας, όμως ο B100 ενδεχομένως να υπερβαίνει σε κόστος τον προκάτοχό του, ο οποίος αυτή τη στιγμή ξεπερνά σε τιμές αγοράς τα 20.000 δολάρια. Οι μετοχές της Nvidia καταγράφουν κέρδη της τάξης του 83% μέσα στο 2024, ενώ την προηγούμενη χρονιά η αξία τους είχε υπερτριπλασιαστεί. Παρ' όλα αυτά, καταγράφονται ανησυχίες για το ενδεχόμενο το χρηματιστηριακό ράλι να ανακοπεί απότομα, σε περίπτωση που οι προβλέψεις των αναλυτών αποδειχτούν υπεραισιόδοξες. Την Τετάρτη, η μετοχή της Nvidia κατέγραψε πτώση της τάξης του 1,1%, κλείνοντας στα 908,88 δολάρια. Ένας άλλος καθοριστικός παράγοντας για την μελλοντική πορεία της εταιρίας έχει να κάνει με το κατά πόσο η Nvidia θα κατορθώσει να εδραιώσει σαφές τεχνολογικό προβάδισμα έναντι των Κινέζων ανταγωνιστών της. Η Ουάσιγκτον εμποδίζει την πρόσβαση της Κίνας στα πλέον προηγμένα chip της Nvidia, με το Πεκίνο να έχει στραφεί στα προϊόντα της Huawei, τα οποία καταγράφουν επιδόσεις αντίστοιχες με το Α100, το chip που παρουσίασε η Nvidia το 2020. Καμία κινεζική εταιρία δεν έχει ισχυριστεί μέχρι στιγμής ότι κατόρθωσε να πιάσει επιδόσεις αντίστοιχες με την τρέχουσα ναυαρχίδα της Nvidia, το Η100, που κυκλοφόρησε το 2022, ενώ εκτιμάται πως η επικείμενη παρουσίαση του Β100 θα ανοίξει ακόμη περισσότερο την ψαλίδα με τις επιλογές που έχει στη διάθεσή της η Κίνα. Μάλιστα, σύμφωνα με ορισμένες αναλύσεις, το προβάδισμα της Nvidia αναμένεται με τον καιρό να καθίσταται γεωμετρικά μεγαλύτερο.
Στο πλαίσιο του ετήσιου συνεδρίου της Nvidia που απευθύνεται στους developers θα έχουμε την ευκαιρία να δούμε το πώς σχεδιάζει να κινηθεί στο άμεσο μέλλον η εταιρία που αυτή τη στιγμή πρωταγωνιστεί στις εξελίξεις στον τομέα της τεχνητής νοημοσύνης. Το συνέδριο θα είναι το πρώτο που θα πραγματοποιηθεί δια ζώσης μετά την πανδημία. Η Nvidia αναμένει τη συμμετοχή 16.000 ανθρώπων στην εκδήλωση, αριθμός περίπου διπλάσιος σε σχέση με εκείνους είχαν αυτοπρόσωπη παρουσία στην εκδήλωση του 2019. Στα τέλη Φεβρουαρίου, η χρηματιστηριακή αποτίμηση της Nvidia ξεπέρασε τα 2 τρισεκατομμύρια δολάρια και πλέον απέχει "μόλις" 400 δισεκατομμύρια δολάρια από το να ξεπεράσει την Apple ως η εταιρία με τη δεύτερη υψηλότερη κεφαλαιοποίηση στο αμερικανικό χρηματιστήριο, πίσω από τη Microsoft, που αναμένεται να διατηρήσει την πρωτοκαθεδρία της. Αναλυτές εκτιμούν ότι τα έσοδα της Nvidia θα καταγράψουν φέτος θεματική αύξηση, κατά 81%, φτάνοντας στα 110 δισεκατομμύρια δολάρια, καθώς οι εταιρίες του χώρου αγοράζουν κατά δεκάδες χιλιάδες τα κορυφαίας τεχνολογίας chip της εταιρίας, προκειμένου να βασίσουν σε αυτά chatbots, προγράμματα δημιουργίας εικόνων και άλλα συστήματα τεχνητής νοημοσύνης. Οι πωλήσεις αυτές είναι διπλάσιες εκείνων που οι αναλυτές προβλέπουν για την Intel, την εταιρία που κυριάρχησε στην εποχή της ραγδαίας ενίσχυσης των προσωπικών υπολογιστών. Το ερώτημα είναι κατά πόσο η Nvidia μπορεί να διατηρήσει το πρόσφατο, εντυπωσιακό προβάδισμά της στον τομέα της τεχνητής νοημοσύνης και να το μεταφράσει σε μακροπρόθεσμα κυρίαρχη θέση σε αυτή τη νέα εποχή της τεχνολογίας. Στο επίκεντρο της προσπάθειας αυτής θα βρεθεί ο νέος κορυφαίος AI επεξεργαστής της εταιρίας, ο οποίος εκτιμάται ότι θα παρουσιαστεί με την επωνυμία Β100. Το chip θα διαδραματίζει κεντρικό ρόλο στα συστήματα τεχνητής νοημοσύνης που διαθέτει στην αγορά η Nvidia και πιθανότατα θα αρχίσει να αποστέλλεται στους πελάτες της εταιρίας μέσα στο 2024. Η ζήτηση για τα προϊόντα της Nvidia υπερβαίνει εδώ και καιρό την προσφορά, καθώς υπάρχουν περιπτώσεις ενδιαφερόμενων στον τομέα της ανάπτυξης λογισμικού που περιμένουν επί μήνες για μια ευκαιρία να χρησιμοποιήσουν υπολογιστές βελτιστοποιημένους για χρήση τεχνητής νοημοσύνης. Είναι απίθανο να ανακοινώσει η Nvidia συγκεκριμένες τιμές στην εκδήλωση της ερχόμενης εβδομάδας, όμως ο B100 ενδεχομένως να υπερβαίνει σε κόστος τον προκάτοχό του, ο οποίος αυτή τη στιγμή ξεπερνά σε τιμές αγοράς τα 20.000 δολάρια. Οι μετοχές της Nvidia καταγράφουν κέρδη της τάξης του 83% μέσα στο 2024, ενώ την προηγούμενη χρονιά η αξία τους είχε υπερτριπλασιαστεί. Παρ' όλα αυτά, καταγράφονται ανησυχίες για το ενδεχόμενο το χρηματιστηριακό ράλι να ανακοπεί απότομα, σε περίπτωση που οι προβλέψεις των αναλυτών αποδειχτούν υπεραισιόδοξες. Την Τετάρτη, η μετοχή της Nvidia κατέγραψε πτώση της τάξης του 1,1%, κλείνοντας στα 908,88 δολάρια. Ένας άλλος καθοριστικός παράγοντας για την μελλοντική πορεία της εταιρίας έχει να κάνει με το κατά πόσο η Nvidia θα κατορθώσει να εδραιώσει σαφές τεχνολογικό προβάδισμα έναντι των Κινέζων ανταγωνιστών της. Η Ουάσιγκτον εμποδίζει την πρόσβαση της Κίνας στα πλέον προηγμένα chip της Nvidia, με το Πεκίνο να έχει στραφεί στα προϊόντα της Huawei, τα οποία καταγράφουν επιδόσεις αντίστοιχες με το Α100, το chip που παρουσίασε η Nvidia το 2020. Καμία κινεζική εταιρία δεν έχει ισχυριστεί μέχρι στιγμής ότι κατόρθωσε να πιάσει επιδόσεις αντίστοιχες με την τρέχουσα ναυαρχίδα της Nvidia, το Η100, που κυκλοφόρησε το 2022, ενώ εκτιμάται πως η επικείμενη παρουσίαση του Β100 θα ανοίξει ακόμη περισσότερο την ψαλίδα με τις επιλογές που έχει στη διάθεσή της η Κίνα. Μάλιστα, σύμφωνα με ορισμένες αναλύσεις, το προβάδισμα της Nvidia αναμένεται με τον καιρό να καθίσταται γεωμετρικά μεγαλύτερο. -
 Το Ευρωπαϊκό Κοινοβούλιο ενέκρινε τον πρώτο κανονισμό σε διεθνές επίπεδο για την τεχνητή νοημοσύνη, με στόχο την προστασία των δικαιωμάτων και της ασφάλειας των πολιτών, καθώς και την ενίσχυση της καινοτομίας στον τομέα αυτό. Όπως είναι ήδη γνωστό, ο κανονισμός θέτει διαφορετικές υποχρεώσεις και περιορισμούς για τα συστήματα τεχνητής νοημοσύνης, ανάλογα με τους κινδύνους που ενέχουν για την κοινωνία. Ορισμένες πρακτικές, όπως η κοινωνική βαθμολόγηση, η χειραγώγηση της ανθρώπινης συμπεριφοράς και η εκμετάλλευση ευάλωτων ατόμων, απαγορεύονται πλήρως. Επίσης, περιορίζεται αυστηρά η χρήση συστημάτων βιομετρικής ταυτοποίησης από τις αρχές επιβολής του νόμου, με εξαιρέσεις μόνο σε συγκεκριμένες περιπτώσεις, όπως η αναζήτηση αγνοουμένων ή η πρόληψη τρομοκρατικών επιθέσεων. Για τα συστήματα τεχνητής νοημοσύνης που θεωρούνται υψηλού κινδύνου, όπως αυτά που χρησιμοποιούνται σε κρίσιμες υποδομές, στην εκπαίδευση, στην απασχόληση και σε βασικές υπηρεσίες, ορίζονται σαφείς περιορισμοί. Αυτά τα συστήματα πρέπει να αξιολογούν και να ελαχιστοποιούν τους κινδύνους, να είναι διαφανή και να εποπτεύονται από ανθρώπους. Οι πολίτες έχουν το δικαίωμα να υποβάλλουν καταγγελίες και να λαμβάνουν εξηγήσεις για τις αποφάσεις που επηρεάζουν τα δικαιώματά τους. Επιπλέον, τα συστήματα τεχνητής νοημοσύνης γενικής χρήσης υπόκεινται σε απαιτήσεις διαφάνειας, όπως η συμμόρφωση με τη νομοθεσία περί πνευματικής ιδιοκτησίας και η δημοσιοποίηση περιλήψεων του περιεχομένου που χρησιμοποιούν για την εκπαίδευση των μοντέλων τους. Για τα ισχυρότερα μοντέλα προβλέπονται πρόσθετες απαιτήσεις, όπως η αξιολόγηση και ο περιορισμός των συστημικών κινδύνων. Ο κανονισμός περιλαμβάνει και μέτρα για την υποστήριξη της καινοτομίας και των μικρομεσαίων επιχειρήσεων. Προβλέπεται η δημιουργία "ρυθμιστικών δοκιμαστηρίων" σε κάθε χώρα, όπου θα μπορούν να δοκιμάζονται τα συστήματα τεχνητής νοημοσύνης σε πραγματικές συνθήκες πριν από τη διάθεσή τους στην αγορά. Σύμφωνα με τους συνεισηγητές του Κοινοβουλίου, ο νέος κανονισμός αποτελεί ορόσημο για την προστασία των δικαιωμάτων των πολιτών και των ευρωπαϊκών αξιών, ενώ παράλληλα δημιουργεί ευκαιρίες για την ανάπτυξη της τεχνητής νοημοσύνης. Ωστόσο, τονίζουν ότι απαιτούνται περαιτέρω προσπάθειες, πέρα από τη νομοθεσία, καθώς η τεχνολογία θα οδηγήσει σε αλλαγές στην κοινωνία, την εκπαίδευση, την εργασία και τη διακυβέρνηση. Ο κανονισμός αναμένεται να εγκριθεί οριστικά πριν από το τέλος της τρέχουσας κοινοβουλευτικής περιόδου και να τεθεί σε πλήρη εφαρμογή 24 μήνες μετά την υιοθέτησή του, με εξαίρεση ορισμένες διατάξεις που θα εφαρμοστούν νωρίτερα. Η έγκριση του κανονισμού για την τεχνητή νοημοσύνη αποτελεί σημαντικό βήμα για τη ρύθμιση μιας ταχέως αναπτυσσόμενης τεχνολογίας με πολλαπλές εφαρμογές και επιπτώσεις. Με το νέο κανονισμό, Ευρωπαϊκή Ένωση επιδιώκει να θέσει τα θεμέλια για μια υπεύθυνη και ασφαλή ανάπτυξη της τεχνητής νοημοσύνης, με γνώμονα την προστασία των πολιτών και την ενίσχυση της καινοτομίας. Διαβάστε ολόκληρο το άρθρο
Το Ευρωπαϊκό Κοινοβούλιο ενέκρινε τον πρώτο κανονισμό σε διεθνές επίπεδο για την τεχνητή νοημοσύνη, με στόχο την προστασία των δικαιωμάτων και της ασφάλειας των πολιτών, καθώς και την ενίσχυση της καινοτομίας στον τομέα αυτό. Όπως είναι ήδη γνωστό, ο κανονισμός θέτει διαφορετικές υποχρεώσεις και περιορισμούς για τα συστήματα τεχνητής νοημοσύνης, ανάλογα με τους κινδύνους που ενέχουν για την κοινωνία. Ορισμένες πρακτικές, όπως η κοινωνική βαθμολόγηση, η χειραγώγηση της ανθρώπινης συμπεριφοράς και η εκμετάλλευση ευάλωτων ατόμων, απαγορεύονται πλήρως. Επίσης, περιορίζεται αυστηρά η χρήση συστημάτων βιομετρικής ταυτοποίησης από τις αρχές επιβολής του νόμου, με εξαιρέσεις μόνο σε συγκεκριμένες περιπτώσεις, όπως η αναζήτηση αγνοουμένων ή η πρόληψη τρομοκρατικών επιθέσεων. Για τα συστήματα τεχνητής νοημοσύνης που θεωρούνται υψηλού κινδύνου, όπως αυτά που χρησιμοποιούνται σε κρίσιμες υποδομές, στην εκπαίδευση, στην απασχόληση και σε βασικές υπηρεσίες, ορίζονται σαφείς περιορισμοί. Αυτά τα συστήματα πρέπει να αξιολογούν και να ελαχιστοποιούν τους κινδύνους, να είναι διαφανή και να εποπτεύονται από ανθρώπους. Οι πολίτες έχουν το δικαίωμα να υποβάλλουν καταγγελίες και να λαμβάνουν εξηγήσεις για τις αποφάσεις που επηρεάζουν τα δικαιώματά τους. Επιπλέον, τα συστήματα τεχνητής νοημοσύνης γενικής χρήσης υπόκεινται σε απαιτήσεις διαφάνειας, όπως η συμμόρφωση με τη νομοθεσία περί πνευματικής ιδιοκτησίας και η δημοσιοποίηση περιλήψεων του περιεχομένου που χρησιμοποιούν για την εκπαίδευση των μοντέλων τους. Για τα ισχυρότερα μοντέλα προβλέπονται πρόσθετες απαιτήσεις, όπως η αξιολόγηση και ο περιορισμός των συστημικών κινδύνων. Ο κανονισμός περιλαμβάνει και μέτρα για την υποστήριξη της καινοτομίας και των μικρομεσαίων επιχειρήσεων. Προβλέπεται η δημιουργία "ρυθμιστικών δοκιμαστηρίων" σε κάθε χώρα, όπου θα μπορούν να δοκιμάζονται τα συστήματα τεχνητής νοημοσύνης σε πραγματικές συνθήκες πριν από τη διάθεσή τους στην αγορά. Σύμφωνα με τους συνεισηγητές του Κοινοβουλίου, ο νέος κανονισμός αποτελεί ορόσημο για την προστασία των δικαιωμάτων των πολιτών και των ευρωπαϊκών αξιών, ενώ παράλληλα δημιουργεί ευκαιρίες για την ανάπτυξη της τεχνητής νοημοσύνης. Ωστόσο, τονίζουν ότι απαιτούνται περαιτέρω προσπάθειες, πέρα από τη νομοθεσία, καθώς η τεχνολογία θα οδηγήσει σε αλλαγές στην κοινωνία, την εκπαίδευση, την εργασία και τη διακυβέρνηση. Ο κανονισμός αναμένεται να εγκριθεί οριστικά πριν από το τέλος της τρέχουσας κοινοβουλευτικής περιόδου και να τεθεί σε πλήρη εφαρμογή 24 μήνες μετά την υιοθέτησή του, με εξαίρεση ορισμένες διατάξεις που θα εφαρμοστούν νωρίτερα. Η έγκριση του κανονισμού για την τεχνητή νοημοσύνη αποτελεί σημαντικό βήμα για τη ρύθμιση μιας ταχέως αναπτυσσόμενης τεχνολογίας με πολλαπλές εφαρμογές και επιπτώσεις. Με το νέο κανονισμό, Ευρωπαϊκή Ένωση επιδιώκει να θέσει τα θεμέλια για μια υπεύθυνη και ασφαλή ανάπτυξη της τεχνητής νοημοσύνης, με γνώμονα την προστασία των πολιτών και την ενίσχυση της καινοτομίας. Διαβάστε ολόκληρο το άρθρο



















