Αναζήτηση στην κοινότητα
Εμφάνιση αποτελεσμάτων για τις ετικέτες 'llama'.
12 αποτελέσματα
-
Ο CEO της Meta, Mark Zuckerberg, ανακοίνωσε μια μεγάλη αναδιάρθρωση του τμήματος τεχνητής νοημοσύνης της εταιρείας, με δέσμευση για την ανάπτυξη "υπερνοημοσύνης" AI. Τα σχετικά συστήματα, θεωρητικά θα μπορούν να ολοκληρώσουν εργασίες εξίσου καλά ή ακόμη καλύτερα από τους ανθρώπους. Με βάση εσωτερικό υπόμνημα που εξέτασε το Bloomberg, ο Zuckerberg ενημέρωσε τους υπαλλήλους ότι οι προσπάθειες γύρω από το AI της Meta, θα υπάγονται σε μια νέα ομάδα με την ονομασία Meta Superintelligence Labs (MSL), την οποία θα ηγείται ο Alexandr Wang, πρώην CEO της startup δεδομένων Scale AI. Ο Wang, τον οποίο ο Zuckerberg χαρακτήρισε ως τον "πιο εντυπωσιακό ιδρυτή της γενιάς του", θα υπηρετήσει ως επικεφαλής AI. Όπως αναφέρεται στην ανακοίνωση, ο Nat Friedman, πρώην CEO του Github, θα "συνεργαστεί με τον Alex για να ηγηθεί" της ομάδας και θα επιβλέπει τις εργασίες της Meta για τα προϊόντα AI και την εφαρμοσμένη έρευνα. "Καθώς ο ρυθμός προόδου της AI επιταχύνεται, η ανάπτυξη υπερνοημοσύνης έρχεται στο προσκήνιο", έγραψε ο Zuckerberg στην εσωτερική ανάρτηση. "Πιστεύω ότι αυτό θα είναι η αρχή μιας νέας εποχής για την ανθρωπότητα, και είμαι πλήρως αφοσιωμένος στο να κάνω ό,τι χρειάζεται για να ηγηθεί η Meta σε αυτόν τον τομέα." Ο Zuckerberg έχει δηλώσει ότι η Meta θα δαπανήσει "εκατοντάδες δισεκατομμύρια" σε AI projects και έρευνα τα επόμενα χρόνια. Ωστόσο, ο ιδρυτής του Facebook εκτιμά επίσης ότι πολλές εταιρείες πιθανόν να προχωρήσουν σε υπερβολικές σπατάλες γύρω από το AI, προσπαθώντας να μη μείνουν πίσω από τις συναρπαστικές εξελίξεις. Η νέα μονάδα MSL θα περιλαμβάνει τις υπάρχουσες ομάδες της εταιρείας που επικεντρώνονται στα μοντέλα μεγάλης γλώσσας, την τεχνολογία που υποστηρίζει τη γενετική AI, καθώς και τα προϊόντα AI και την ερευνητική ομάδα Fundamental AI Research (FAIR). Η Meta δημιουργεί επίσης ένα "νέο εργαστήριο επικεντρωμένο στην ανάπτυξη της επόμενης γενιάς των μοντέλων μας", έγραψε ο Zuckerberg στο ίδιο υπόμνημα. Αφήνοντας νει η κορυφαία προτεραιότητα του Zuckerberg φέτος, καθώς ανταγωνίζεται με αντιπάλους όπως η OpenAI και η Google της Alphabet για την ανάπτυξη προηγμένων μοντέλων και βοηθών AI που ελπίζει ότι μια μέρα θα γίνουν πανταχού παρόντες. Η δαπάνη αυτή έχει έρθει με τη μορφή υποδομών, όπως τσιπ και κέντρα δεδομένων, και με την πρόσληψη προσωπικού και εξαγορές. Νωρίτερα αυτό το μήνα, η Meta επένδυσε 14,3 δισεκατομμύρια δολάρια στην Scale AI και προσέλαβε τον Wang στη διαδικασία. Η Meta είχε επίσης συνομιλίες για συμφωνίες με την Perplexity AI και την Runway AI, και αναμένεται να εξαγοράσει την PlayAI, μια μικρή startup που χρησιμοποιεί τεχνητή νοημοσύνη για την αναπαραγωγή φωνών. Ο Zuckerberg έχει εργαστεί προσωπικά για την προσέλκυση ταλέντων στις ομάδες AI της Meta. Έχει φιλοξενήσει υποψήφιους στα σπίτια του στο Palo Alto της Καλιφόρνια και στη Λίμνη Tahoe και έχει ηγηθεί ο ίδιος της αρχικής προσέγγισης. Η Meta έχει προσφέρει σε ορισμένους ερευνητές πακέτα αποζημίωσης, συμπεριλαμβανομένων των μετοχών, αξίας δεκάδων εκατομμυρίων δολαρίων - ένα σημάδι της δέσμευσης της Meta στην AI και του ανταγωνισμού στον κλάδο. Εκτός από τη νέα δομή, ο Zuckerberg ανακοίνωσε 11 νέες προσλήψεις για την ομάδα, συμπεριλαμβανομένων ερευνητών και μηχανικών λογισμικού από την OpenAI, την Anthropic και την Google. Η ομάδα περιλαμβάνει πρώην ερευνητές της DeepMind, Jack Rae και Pei Sun, αρκετούς ερευνητές της OpenAI και τον Joel Pobar της Anthropic, έναν μηχανικό λογισμικού που εργαζόταν προηγουμένως στη Meta για περισσότερο από μια δεκαετία. Διαβάστε ολόκληρο το άρθρο
-
 Τα σχετικά συστήματα, θεωρητικά θα μπορούν να ολοκληρώσουν εργασίες εξίσου καλά ή ακόμη καλύτερα από τους ανθρώπους. Με βάση εσωτερικό υπόμνημα που εξέτασε το Bloomberg, ο Zuckerberg ενημέρωσε τους υπαλλήλους ότι οι προσπάθειες γύρω από το AI της Meta, θα υπάγονται σε μια νέα ομάδα με την ονομασία Meta Superintelligence Labs (MSL), την οποία θα ηγείται ο Alexandr Wang, πρώην CEO της startup δεδομένων Scale AI. Ο Wang, τον οποίο ο Zuckerberg χαρακτήρισε ως τον "πιο εντυπωσιακό ιδρυτή της γενιάς του", θα υπηρετήσει ως επικεφαλής AI. Όπως αναφέρεται στην ανακοίνωση, ο Nat Friedman, πρώην CEO του Github, θα "συνεργαστεί με τον Alex για να ηγηθεί" της ομάδας και θα επιβλέπει τις εργασίες της Meta για τα προϊόντα AI και την εφαρμοσμένη έρευνα. "Καθώς ο ρυθμός προόδου της AI επιταχύνεται, η ανάπτυξη υπερνοημοσύνης έρχεται στο προσκήνιο", έγραψε ο Zuckerberg στην εσωτερική ανάρτηση. "Πιστεύω ότι αυτό θα είναι η αρχή μιας νέας εποχής για την ανθρωπότητα, και είμαι πλήρως αφοσιωμένος στο να κάνω ό,τι χρειάζεται για να ηγηθεί η Meta σε αυτόν τον τομέα." Ο Zuckerberg έχει δηλώσει ότι η Meta θα δαπανήσει "εκατοντάδες δισεκατομμύρια" σε AI projects και έρευνα τα επόμενα χρόνια. Ωστόσο, ο ιδρυτής του Facebook εκτιμά επίσης ότι πολλές εταιρείες πιθανόν να προχωρήσουν σε υπερβολικές σπατάλες γύρω από το AI, προσπαθώντας να μη μείνουν πίσω από τις συναρπαστικές εξελίξεις. Η νέα μονάδα MSL θα περιλαμβάνει τις υπάρχουσες ομάδες της εταιρείας που επικεντρώνονται στα μοντέλα μεγάλης γλώσσας, την τεχνολογία που υποστηρίζει τη γενετική AI, καθώς και τα προϊόντα AI και την ερευνητική ομάδα Fundamental AI Research (FAIR). Η Meta δημιουργεί επίσης ένα "νέο εργαστήριο επικεντρωμένο στην ανάπτυξη της επόμενης γενιάς των μοντέλων μας", έγραψε ο Zuckerberg στο ίδιο υπόμνημα. Αφήνοντας νει η κορυφαία προτεραιότητα του Zuckerberg φέτος, καθώς ανταγωνίζεται με αντιπάλους όπως η OpenAI και η Google της Alphabet για την ανάπτυξη προηγμένων μοντέλων και βοηθών AI που ελπίζει ότι μια μέρα θα γίνουν πανταχού παρόντες. Η δαπάνη αυτή έχει έρθει με τη μορφή υποδομών, όπως τσιπ και κέντρα δεδομένων, και με την πρόσληψη προσωπικού και εξαγορές. Νωρίτερα αυτό το μήνα, η Meta επένδυσε 14,3 δισεκατομμύρια δολάρια στην Scale AI και προσέλαβε τον Wang στη διαδικασία. Η Meta είχε επίσης συνομιλίες για συμφωνίες με την Perplexity AI και την Runway AI, και αναμένεται να εξαγοράσει την PlayAI, μια μικρή startup που χρησιμοποιεί τεχνητή νοημοσύνη για την αναπαραγωγή φωνών. Ο Zuckerberg έχει εργαστεί προσωπικά για την προσέλκυση ταλέντων στις ομάδες AI της Meta. Έχει φιλοξενήσει υποψήφιους στα σπίτια του στο Palo Alto της Καλιφόρνια και στη Λίμνη Tahoe και έχει ηγηθεί ο ίδιος της αρχικής προσέγγισης. Η Meta έχει προσφέρει σε ορισμένους ερευνητές πακέτα αποζημίωσης, συμπεριλαμβανομένων των μετοχών, αξίας δεκάδων εκατομμυρίων δολαρίων - ένα σημάδι της δέσμευσης της Meta στην AI και του ανταγωνισμού στον κλάδο. Εκτός από τη νέα δομή, ο Zuckerberg ανακοίνωσε 11 νέες προσλήψεις για την ομάδα, συμπεριλαμβανομένων ερευνητών και μηχανικών λογισμικού από την OpenAI, την Anthropic και την Google. Η ομάδα περιλαμβάνει πρώην ερευνητές της DeepMind, Jack Rae και Pei Sun, αρκετούς ερευνητές της OpenAI και τον Joel Pobar της Anthropic, έναν μηχανικό λογισμικού που εργαζόταν προηγουμένως στη Meta για περισσότερο από μια δεκαετία.
Τα σχετικά συστήματα, θεωρητικά θα μπορούν να ολοκληρώσουν εργασίες εξίσου καλά ή ακόμη καλύτερα από τους ανθρώπους. Με βάση εσωτερικό υπόμνημα που εξέτασε το Bloomberg, ο Zuckerberg ενημέρωσε τους υπαλλήλους ότι οι προσπάθειες γύρω από το AI της Meta, θα υπάγονται σε μια νέα ομάδα με την ονομασία Meta Superintelligence Labs (MSL), την οποία θα ηγείται ο Alexandr Wang, πρώην CEO της startup δεδομένων Scale AI. Ο Wang, τον οποίο ο Zuckerberg χαρακτήρισε ως τον "πιο εντυπωσιακό ιδρυτή της γενιάς του", θα υπηρετήσει ως επικεφαλής AI. Όπως αναφέρεται στην ανακοίνωση, ο Nat Friedman, πρώην CEO του Github, θα "συνεργαστεί με τον Alex για να ηγηθεί" της ομάδας και θα επιβλέπει τις εργασίες της Meta για τα προϊόντα AI και την εφαρμοσμένη έρευνα. "Καθώς ο ρυθμός προόδου της AI επιταχύνεται, η ανάπτυξη υπερνοημοσύνης έρχεται στο προσκήνιο", έγραψε ο Zuckerberg στην εσωτερική ανάρτηση. "Πιστεύω ότι αυτό θα είναι η αρχή μιας νέας εποχής για την ανθρωπότητα, και είμαι πλήρως αφοσιωμένος στο να κάνω ό,τι χρειάζεται για να ηγηθεί η Meta σε αυτόν τον τομέα." Ο Zuckerberg έχει δηλώσει ότι η Meta θα δαπανήσει "εκατοντάδες δισεκατομμύρια" σε AI projects και έρευνα τα επόμενα χρόνια. Ωστόσο, ο ιδρυτής του Facebook εκτιμά επίσης ότι πολλές εταιρείες πιθανόν να προχωρήσουν σε υπερβολικές σπατάλες γύρω από το AI, προσπαθώντας να μη μείνουν πίσω από τις συναρπαστικές εξελίξεις. Η νέα μονάδα MSL θα περιλαμβάνει τις υπάρχουσες ομάδες της εταιρείας που επικεντρώνονται στα μοντέλα μεγάλης γλώσσας, την τεχνολογία που υποστηρίζει τη γενετική AI, καθώς και τα προϊόντα AI και την ερευνητική ομάδα Fundamental AI Research (FAIR). Η Meta δημιουργεί επίσης ένα "νέο εργαστήριο επικεντρωμένο στην ανάπτυξη της επόμενης γενιάς των μοντέλων μας", έγραψε ο Zuckerberg στο ίδιο υπόμνημα. Αφήνοντας νει η κορυφαία προτεραιότητα του Zuckerberg φέτος, καθώς ανταγωνίζεται με αντιπάλους όπως η OpenAI και η Google της Alphabet για την ανάπτυξη προηγμένων μοντέλων και βοηθών AI που ελπίζει ότι μια μέρα θα γίνουν πανταχού παρόντες. Η δαπάνη αυτή έχει έρθει με τη μορφή υποδομών, όπως τσιπ και κέντρα δεδομένων, και με την πρόσληψη προσωπικού και εξαγορές. Νωρίτερα αυτό το μήνα, η Meta επένδυσε 14,3 δισεκατομμύρια δολάρια στην Scale AI και προσέλαβε τον Wang στη διαδικασία. Η Meta είχε επίσης συνομιλίες για συμφωνίες με την Perplexity AI και την Runway AI, και αναμένεται να εξαγοράσει την PlayAI, μια μικρή startup που χρησιμοποιεί τεχνητή νοημοσύνη για την αναπαραγωγή φωνών. Ο Zuckerberg έχει εργαστεί προσωπικά για την προσέλκυση ταλέντων στις ομάδες AI της Meta. Έχει φιλοξενήσει υποψήφιους στα σπίτια του στο Palo Alto της Καλιφόρνια και στη Λίμνη Tahoe και έχει ηγηθεί ο ίδιος της αρχικής προσέγγισης. Η Meta έχει προσφέρει σε ορισμένους ερευνητές πακέτα αποζημίωσης, συμπεριλαμβανομένων των μετοχών, αξίας δεκάδων εκατομμυρίων δολαρίων - ένα σημάδι της δέσμευσης της Meta στην AI και του ανταγωνισμού στον κλάδο. Εκτός από τη νέα δομή, ο Zuckerberg ανακοίνωσε 11 νέες προσλήψεις για την ομάδα, συμπεριλαμβανομένων ερευνητών και μηχανικών λογισμικού από την OpenAI, την Anthropic και την Google. Η ομάδα περιλαμβάνει πρώην ερευνητές της DeepMind, Jack Rae και Pei Sun, αρκετούς ερευνητές της OpenAI και τον Joel Pobar της Anthropic, έναν μηχανικό λογισμικού που εργαζόταν προηγουμένως στη Meta για περισσότερο από μια δεκαετία. -
 Ο διευθύνων σύμβουλος της Microsoft, Satya Nadella, αποκάλυψε ότι έως και το 30% του κώδικα της εταιρείας γράφεται πλέον από τεχνητή νοημοσύνη, σηματοδοτώντας μια σημαντική αλλαγή στην ανάπτυξη λογισμικού. Η αποκάλυψη πραγματοποιήθηκε κατά τη διάρκεια συζήτησης με τον Mark Zuckerberg της Meta στο εναρκτήριο συνέδριο LlamaCon AI για προγραμματιστές στο Menlo Park της Καλιφόρνιας. "Θα έλεγα ότι ίσως το 20%, 30% του κώδικα που βρίσκεται σήμερα στα αποθετήρια μας και σε ορισμένα από τα έργα μας πιθανότατα γράφονται εξ ολοκλήρου από λογισμικό", δήλωσε χαρακτηριστικά ο Nadella. Πρόσθεσε επίσης ότι το ποσοστό του κώδικα που γράφεται από τεχνητή νοημοσύνη στη Microsoft αυξάνεται σταθερά. Στη διάρκεια της συνομιλίας τους, ο Nadella απηύθυνε στον Zuckerberg ερώτηση σχετικά με το ποσοστό του κώδικα της Meta που δημιουργείται από συστήματα τεχνητής νοημοσύνης. Ο διευθύνων σύμβουλος της Meta απάντησε ότι δεν γνώριζε το ακριβές ποσοστό, αλλά αποκάλυψε ότι η εταιρεία του αναπτύσσει ένα μοντέλο τεχνητής νοημοσύνης που θα μπορεί να δημιουργεί μελλοντικές εκδόσεις της οικογένειας μοντέλων Llama της εταιρείας. "Το στοίχημά μας είναι ότι τον επόμενο χρόνο πιθανώς... ίσως το μισό της ανάπτυξης θα γίνεται από τεχνητή νοημοσύνη, αντί από ανθρώπους, και αυτό απλώς θα συνεχίσει να αυξάνεται από εκεί και πέρα", τόνισε ο Zuckerberg. Η Microsoft και η Meta απασχολούν μαζί δεκάδες χιλιάδες προγραμματιστές, αλλά είναι οι πιο πρόσφατες εταιρείες που συζητούν πώς η τεχνητή νοημοσύνη αντικαθιστά μέρος της εργασίας που παραδοσιακά εκτελείται από ανθρώπους. Από την κυκλοφορία του ChatGPT της OpenAI στα τέλη του 2022, οι άνθρωποι έχουν στραφεί στην τεχνητή νοημοσύνη για διάφορες εργασίες, συμπεριλαμβανομένης της εξυπηρέτησης πελατών, της δημιουργίας προτάσεων πωλήσεων και της ανάπτυξης λογισμικού. Ο διευθύνων σύμβουλος της Google, Sundar Pichai, δήλωσε τον Οκτώβριο ότι περισσότερο από το 25% του νέου κώδικα γράφεται από τεχνητή νοημοσύνη. Νωρίτερα αυτό το μήνα, ο διευθύνων σύμβουλος της Shopify, Tobi Lutke, είπε στους εργαζόμενους ότι θα πρέπει να αποδείξουν ότι η τεχνητή νοημοσύνη δεν μπορεί να κάνει μια δουλειά πριν ζητήσουν περισσότερο προσωπικό. Παρομοίως, ο διευθύνων σύμβουλος της Duolingo, Luis von Ahn, ανακοίνωσε τη Δευτέρα σε ένα υπόμνημα ότι η εταιρεία εκμάθησης γλωσσών θα στραφεί σταδιακά στην τεχνητή νοημοσύνη αντί για τους ανθρώπους εξωτερικούς συνεργάτες. Νωρίτερα αυτό το μήνα, το CNBC και άλλα μέσα ενημέρωσης ανέφεραν ότι η OpenAI βρισκόταν σε συνομιλίες για την εξαγορά της Windsurf, μιας νεοφυούς εταιρείας με λογισμικό "vibe coding" που παράγει ολόκληρα προγράμματα με λίγες λέξεις ως prompts. Το όραμα είναι ότι με τις μηχανές να βοηθούν στη συγγραφή κώδικα, οι οργανισμοί θα μπορούν να παράγουν περισσότερο και καλύτερο λογισμικό. Διαβάστε ολόκληρο το άρθρο
Ο διευθύνων σύμβουλος της Microsoft, Satya Nadella, αποκάλυψε ότι έως και το 30% του κώδικα της εταιρείας γράφεται πλέον από τεχνητή νοημοσύνη, σηματοδοτώντας μια σημαντική αλλαγή στην ανάπτυξη λογισμικού. Η αποκάλυψη πραγματοποιήθηκε κατά τη διάρκεια συζήτησης με τον Mark Zuckerberg της Meta στο εναρκτήριο συνέδριο LlamaCon AI για προγραμματιστές στο Menlo Park της Καλιφόρνιας. "Θα έλεγα ότι ίσως το 20%, 30% του κώδικα που βρίσκεται σήμερα στα αποθετήρια μας και σε ορισμένα από τα έργα μας πιθανότατα γράφονται εξ ολοκλήρου από λογισμικό", δήλωσε χαρακτηριστικά ο Nadella. Πρόσθεσε επίσης ότι το ποσοστό του κώδικα που γράφεται από τεχνητή νοημοσύνη στη Microsoft αυξάνεται σταθερά. Στη διάρκεια της συνομιλίας τους, ο Nadella απηύθυνε στον Zuckerberg ερώτηση σχετικά με το ποσοστό του κώδικα της Meta που δημιουργείται από συστήματα τεχνητής νοημοσύνης. Ο διευθύνων σύμβουλος της Meta απάντησε ότι δεν γνώριζε το ακριβές ποσοστό, αλλά αποκάλυψε ότι η εταιρεία του αναπτύσσει ένα μοντέλο τεχνητής νοημοσύνης που θα μπορεί να δημιουργεί μελλοντικές εκδόσεις της οικογένειας μοντέλων Llama της εταιρείας. "Το στοίχημά μας είναι ότι τον επόμενο χρόνο πιθανώς... ίσως το μισό της ανάπτυξης θα γίνεται από τεχνητή νοημοσύνη, αντί από ανθρώπους, και αυτό απλώς θα συνεχίσει να αυξάνεται από εκεί και πέρα", τόνισε ο Zuckerberg. Η Microsoft και η Meta απασχολούν μαζί δεκάδες χιλιάδες προγραμματιστές, αλλά είναι οι πιο πρόσφατες εταιρείες που συζητούν πώς η τεχνητή νοημοσύνη αντικαθιστά μέρος της εργασίας που παραδοσιακά εκτελείται από ανθρώπους. Από την κυκλοφορία του ChatGPT της OpenAI στα τέλη του 2022, οι άνθρωποι έχουν στραφεί στην τεχνητή νοημοσύνη για διάφορες εργασίες, συμπεριλαμβανομένης της εξυπηρέτησης πελατών, της δημιουργίας προτάσεων πωλήσεων και της ανάπτυξης λογισμικού. Ο διευθύνων σύμβουλος της Google, Sundar Pichai, δήλωσε τον Οκτώβριο ότι περισσότερο από το 25% του νέου κώδικα γράφεται από τεχνητή νοημοσύνη. Νωρίτερα αυτό το μήνα, ο διευθύνων σύμβουλος της Shopify, Tobi Lutke, είπε στους εργαζόμενους ότι θα πρέπει να αποδείξουν ότι η τεχνητή νοημοσύνη δεν μπορεί να κάνει μια δουλειά πριν ζητήσουν περισσότερο προσωπικό. Παρομοίως, ο διευθύνων σύμβουλος της Duolingo, Luis von Ahn, ανακοίνωσε τη Δευτέρα σε ένα υπόμνημα ότι η εταιρεία εκμάθησης γλωσσών θα στραφεί σταδιακά στην τεχνητή νοημοσύνη αντί για τους ανθρώπους εξωτερικούς συνεργάτες. Νωρίτερα αυτό το μήνα, το CNBC και άλλα μέσα ενημέρωσης ανέφεραν ότι η OpenAI βρισκόταν σε συνομιλίες για την εξαγορά της Windsurf, μιας νεοφυούς εταιρείας με λογισμικό "vibe coding" που παράγει ολόκληρα προγράμματα με λίγες λέξεις ως prompts. Το όραμα είναι ότι με τις μηχανές να βοηθούν στη συγγραφή κώδικα, οι οργανισμοί θα μπορούν να παράγουν περισσότερο και καλύτερο λογισμικό. Διαβάστε ολόκληρο το άρθρο -
 Η αποκάλυψη πραγματοποιήθηκε κατά τη διάρκεια συζήτησης με τον Mark Zuckerberg της Meta στο εναρκτήριο συνέδριο LlamaCon AI για προγραμματιστές στο Menlo Park της Καλιφόρνιας. "Θα έλεγα ότι ίσως το 20%, 30% του κώδικα που βρίσκεται σήμερα στα αποθετήρια μας και σε ορισμένα από τα έργα μας πιθανότατα γράφονται εξ ολοκλήρου από λογισμικό", δήλωσε χαρακτηριστικά ο Nadella. Πρόσθεσε επίσης ότι το ποσοστό του κώδικα που γράφεται από τεχνητή νοημοσύνη στη Microsoft αυξάνεται σταθερά. Στη διάρκεια της συνομιλίας τους, ο Nadella απηύθυνε στον Zuckerberg ερώτηση σχετικά με το ποσοστό του κώδικα της Meta που δημιουργείται από συστήματα τεχνητής νοημοσύνης. Ο διευθύνων σύμβουλος της Meta απάντησε ότι δεν γνώριζε το ακριβές ποσοστό, αλλά αποκάλυψε ότι η εταιρεία του αναπτύσσει ένα μοντέλο τεχνητής νοημοσύνης που θα μπορεί να δημιουργεί μελλοντικές εκδόσεις της οικογένειας μοντέλων Llama της εταιρείας. "Το στοίχημά μας είναι ότι τον επόμενο χρόνο πιθανώς... ίσως το μισό της ανάπτυξης θα γίνεται από τεχνητή νοημοσύνη, αντί από ανθρώπους, και αυτό απλώς θα συνεχίσει να αυξάνεται από εκεί και πέρα", τόνισε ο Zuckerberg. Η Microsoft και η Meta απασχολούν μαζί δεκάδες χιλιάδες προγραμματιστές, αλλά είναι οι πιο πρόσφατες εταιρείες που συζητούν πώς η τεχνητή νοημοσύνη αντικαθιστά μέρος της εργασίας που παραδοσιακά εκτελείται από ανθρώπους. Από την κυκλοφορία του ChatGPT της OpenAI στα τέλη του 2022, οι άνθρωποι έχουν στραφεί στην τεχνητή νοημοσύνη για διάφορες εργασίες, συμπεριλαμβανομένης της εξυπηρέτησης πελατών, της δημιουργίας προτάσεων πωλήσεων και της ανάπτυξης λογισμικού. Ο διευθύνων σύμβουλος της Google, Sundar Pichai, δήλωσε τον Οκτώβριο ότι περισσότερο από το 25% του νέου κώδικα γράφεται από τεχνητή νοημοσύνη. Νωρίτερα αυτό το μήνα, ο διευθύνων σύμβουλος της Shopify, Tobi Lutke, είπε στους εργαζόμενους ότι θα πρέπει να αποδείξουν ότι η τεχνητή νοημοσύνη δεν μπορεί να κάνει μια δουλειά πριν ζητήσουν περισσότερο προσωπικό. Παρομοίως, ο διευθύνων σύμβουλος της Duolingo, Luis von Ahn, ανακοίνωσε τη Δευτέρα σε ένα υπόμνημα ότι η εταιρεία εκμάθησης γλωσσών θα στραφεί σταδιακά στην τεχνητή νοημοσύνη αντί για τους ανθρώπους εξωτερικούς συνεργάτες. Νωρίτερα αυτό το μήνα, το CNBC και άλλα μέσα ενημέρωσης ανέφεραν ότι η OpenAI βρισκόταν σε συνομιλίες για την εξαγορά της Windsurf, μιας νεοφυούς εταιρείας με λογισμικό "vibe coding" που παράγει ολόκληρα προγράμματα με λίγες λέξεις ως prompts. Το όραμα είναι ότι με τις μηχανές να βοηθούν στη συγγραφή κώδικα, οι οργανισμοί θα μπορούν να παράγουν περισσότερο και καλύτερο λογισμικό.
Η αποκάλυψη πραγματοποιήθηκε κατά τη διάρκεια συζήτησης με τον Mark Zuckerberg της Meta στο εναρκτήριο συνέδριο LlamaCon AI για προγραμματιστές στο Menlo Park της Καλιφόρνιας. "Θα έλεγα ότι ίσως το 20%, 30% του κώδικα που βρίσκεται σήμερα στα αποθετήρια μας και σε ορισμένα από τα έργα μας πιθανότατα γράφονται εξ ολοκλήρου από λογισμικό", δήλωσε χαρακτηριστικά ο Nadella. Πρόσθεσε επίσης ότι το ποσοστό του κώδικα που γράφεται από τεχνητή νοημοσύνη στη Microsoft αυξάνεται σταθερά. Στη διάρκεια της συνομιλίας τους, ο Nadella απηύθυνε στον Zuckerberg ερώτηση σχετικά με το ποσοστό του κώδικα της Meta που δημιουργείται από συστήματα τεχνητής νοημοσύνης. Ο διευθύνων σύμβουλος της Meta απάντησε ότι δεν γνώριζε το ακριβές ποσοστό, αλλά αποκάλυψε ότι η εταιρεία του αναπτύσσει ένα μοντέλο τεχνητής νοημοσύνης που θα μπορεί να δημιουργεί μελλοντικές εκδόσεις της οικογένειας μοντέλων Llama της εταιρείας. "Το στοίχημά μας είναι ότι τον επόμενο χρόνο πιθανώς... ίσως το μισό της ανάπτυξης θα γίνεται από τεχνητή νοημοσύνη, αντί από ανθρώπους, και αυτό απλώς θα συνεχίσει να αυξάνεται από εκεί και πέρα", τόνισε ο Zuckerberg. Η Microsoft και η Meta απασχολούν μαζί δεκάδες χιλιάδες προγραμματιστές, αλλά είναι οι πιο πρόσφατες εταιρείες που συζητούν πώς η τεχνητή νοημοσύνη αντικαθιστά μέρος της εργασίας που παραδοσιακά εκτελείται από ανθρώπους. Από την κυκλοφορία του ChatGPT της OpenAI στα τέλη του 2022, οι άνθρωποι έχουν στραφεί στην τεχνητή νοημοσύνη για διάφορες εργασίες, συμπεριλαμβανομένης της εξυπηρέτησης πελατών, της δημιουργίας προτάσεων πωλήσεων και της ανάπτυξης λογισμικού. Ο διευθύνων σύμβουλος της Google, Sundar Pichai, δήλωσε τον Οκτώβριο ότι περισσότερο από το 25% του νέου κώδικα γράφεται από τεχνητή νοημοσύνη. Νωρίτερα αυτό το μήνα, ο διευθύνων σύμβουλος της Shopify, Tobi Lutke, είπε στους εργαζόμενους ότι θα πρέπει να αποδείξουν ότι η τεχνητή νοημοσύνη δεν μπορεί να κάνει μια δουλειά πριν ζητήσουν περισσότερο προσωπικό. Παρομοίως, ο διευθύνων σύμβουλος της Duolingo, Luis von Ahn, ανακοίνωσε τη Δευτέρα σε ένα υπόμνημα ότι η εταιρεία εκμάθησης γλωσσών θα στραφεί σταδιακά στην τεχνητή νοημοσύνη αντί για τους ανθρώπους εξωτερικούς συνεργάτες. Νωρίτερα αυτό το μήνα, το CNBC και άλλα μέσα ενημέρωσης ανέφεραν ότι η OpenAI βρισκόταν σε συνομιλίες για την εξαγορά της Windsurf, μιας νεοφυούς εταιρείας με λογισμικό "vibe coding" που παράγει ολόκληρα προγράμματα με λίγες λέξεις ως prompts. Το όραμα είναι ότι με τις μηχανές να βοηθούν στη συγγραφή κώδικα, οι οργανισμοί θα μπορούν να παράγουν περισσότερο και καλύτερο λογισμικό. -
Η Meta κυκλοφόρησε μια αυτόνομη εφαρμογή AI assistant με κοινωνικά χαρακτηριστικά, αποκαλύπτοντας μια νέα προσέγγιση στην αλληλεπίδραση με την τεχνητή νοημοσύνη. Η αυτόνομη εφαρμογή τεχνητής νοημοσύνης της Meta λειτουργεί ως ανταγωνιστής του ChatGPT, προσφέροντας τις αναμενόμενες λειτουργίες ενός AI βοηθού αλλά με μια σημαντική καινοτομία: ένα κοινωνικό feed ανακαλύψεων. Η εφαρμογή είναι διαθέσιμη για download από το Play Store του Android και το App Store του iPhone. Σύμφωνα με τον Connor Hayes, Αντιπρόεδρο προϊόντων της Meta, η νέα εφαρμογή Meta AI περιλαμβάνει ένα Discover feed που προσθέτει μια AI διάσταση στα κοινωνικά δίκτυα. Σε αυτό το feed, οι χρήστες μπορούν να δουν αλληλεπιδράσεις άλλων ανθρώπων με το Meta AI, συμπεριλαμβανομένων των φίλων τους από το Instagram και το Facebook, που έχουν επιλέξει να μοιραστούν. Οι χρήστες έχουν τη δυνατότητα να κάνουν like, να σχολιάσουν, να μοιραστούν ή να τροποποιήσουν αυτές τις AI κοινοποιήσεις. «Στόχος μας είναι να απομυθοποιήσουμε την τεχνητή νοημοσύνη και να δείξουμε στον κόσμο τις πραγματικές δυνατότητες που τους προσφέρει», δηλώνει ο Connor Hayes, Αντιπρόεδρος Προϊόντος της Meta. Η σύγκλιση των AI chatbots με τα κοινωνικά δίκτυα φαίνεται να αποτελεί μια αναδυόμενη τάση στον κλάδο. Το X του Elon Musk έχει ήδη ενσωματώσει το Grok, ενώ η OpenAI σχεδιάζει να προσθέσει ένα κοινωνικό feed στο ChatGPT. Η εφαρμογή Meta AI δίνει ιδιαίτερη έμφαση στη λειτουργία φωνής. Μια προαιρετική beta έκδοση καθιστά τη φωνή του Meta AI πιο φυσική στη συνομιλία, παρόμοια με την προηγμένη λειτουργία φωνής του ChatGPT, αν και η έκδοση της Meta δεν έχει προς το παρόν πρόσβαση σε πληροφορίες από το διαδίκτυο. Η προαιρετική λειτουργία φωνής βασίζεται στο ερευνητικό μοντέλο AI "full-duplex" που έχει δημοσιεύσει η Meta. Έχει σχεδιαστεί για να επιτρέπει "πλούσιο συγχρονισμό με τη μορφή γρήγορης και δυναμικής εναλλαγής ομιλίας, επικαλυπτόμενου λόγου και ανάδρασης". Κατά τη διάρκεια μιας σύντομης επίδειξης, υπήρχε αισθητή διαφορά στο επίπεδο προσωπικότητας που μετέδιδε η λειτουργία full-duplex σε σύγκριση με την τυπική λειτουργία φωνής. Αμφότερες οι λειτουργίες φωνής είναι διαθέσιμες αρχικά στις ΗΠΑ, τον Καναδά, την Αυστραλία και τη Νέα Ζηλανδία. Στις ΗΠΑ και τον Καναδά, η Meta χρησιμοποιεί πληροφορίες από τα προφίλ χρηστών του Facebook και Instagram για να εξατομικεύσει τις απαντήσεις του βοηθού της. Θεωρητικά, αυτό σημαίνει ότι ο τρόπος χρήσης και των δύο εφαρμογών θα επηρεάζει τα αποτελέσματα που λαμβάνουν οι χρήστες από το Meta AI. Όπως το ChatGPT, οι χρήστες μπορούν επίσης να δώσουν οδηγίες στο Meta AI να θυμάται συγκεκριμένες λεπτομέρειες για αυτούς. Η εφαρμογή τροφοδοτείται από μια προσαρμοσμένη από τη Meta έκδοση του Llama 4. Μέχρι στιγμής, οι περισσότεροι άνθρωποι έχουν έρθει σε επαφή με το Meta AI μέσω της ενσωμάτωσής του σε τμήματα του Instagram, του Facebook και του WhatsApp. Ο Hayes αναφέρει ότι το chatbot έχει φτάσει "σχεδόν" το ένα δισεκατομμύριο χρήστες με αυτόν τον τρόπο, αν και παραδέχεται ότι μια αυτόνομη εφαρμογή είναι "ο πιο διαισθητικός τρόπος αλληλεπίδρασης με έναν AI βοηθό". Ενδιαφέρον παρουσιάζει το γεγονός ότι η εφαρμογή Meta AI δεν κυκλοφορεί ως εντελώς νέα εφαρμογή, αλλά αντικαθιστά την υπάρχουσα εφαρμογή View για τα έξυπνα γυαλιά Meta Ray-Ban. Μια ειδική καρτέλα στο νέο περιβάλλον επιτρέπει την πρόσβαση στις ίδιες πληροφορίες με την προηγούμενη έκδοση της εφαρμογής View για τα γυαλιά. Σύμφωνα με τον Hayes, η Meta πήρε την απόφαση να συγχωνεύσει την εφαρμογή συνοδείας των γυαλιών με τον βοηθό της επειδή η εταιρεία βλέπει τον οδικό χάρτη προϊόντων AI ως "οδικό χάρτη software και hardware με την πάροδο του χρόνου". Τα γυαλιά Meta Ray-Ban χρησιμοποιούν ήδη AI για να αναγνωρίζουν τι βλέπετε και πρόσφατα προστέθηκε η δυνατότητα μετάφρασης μεταξύ γλωσσών σε πραγματικό χρόνο. Η Meta σχεδιάζει να κυκλοφορήσει αργότερα φέτος ένα πιο ακριβό ζευγάρι με μια μικρή οθόνη head-up display. View full article
-
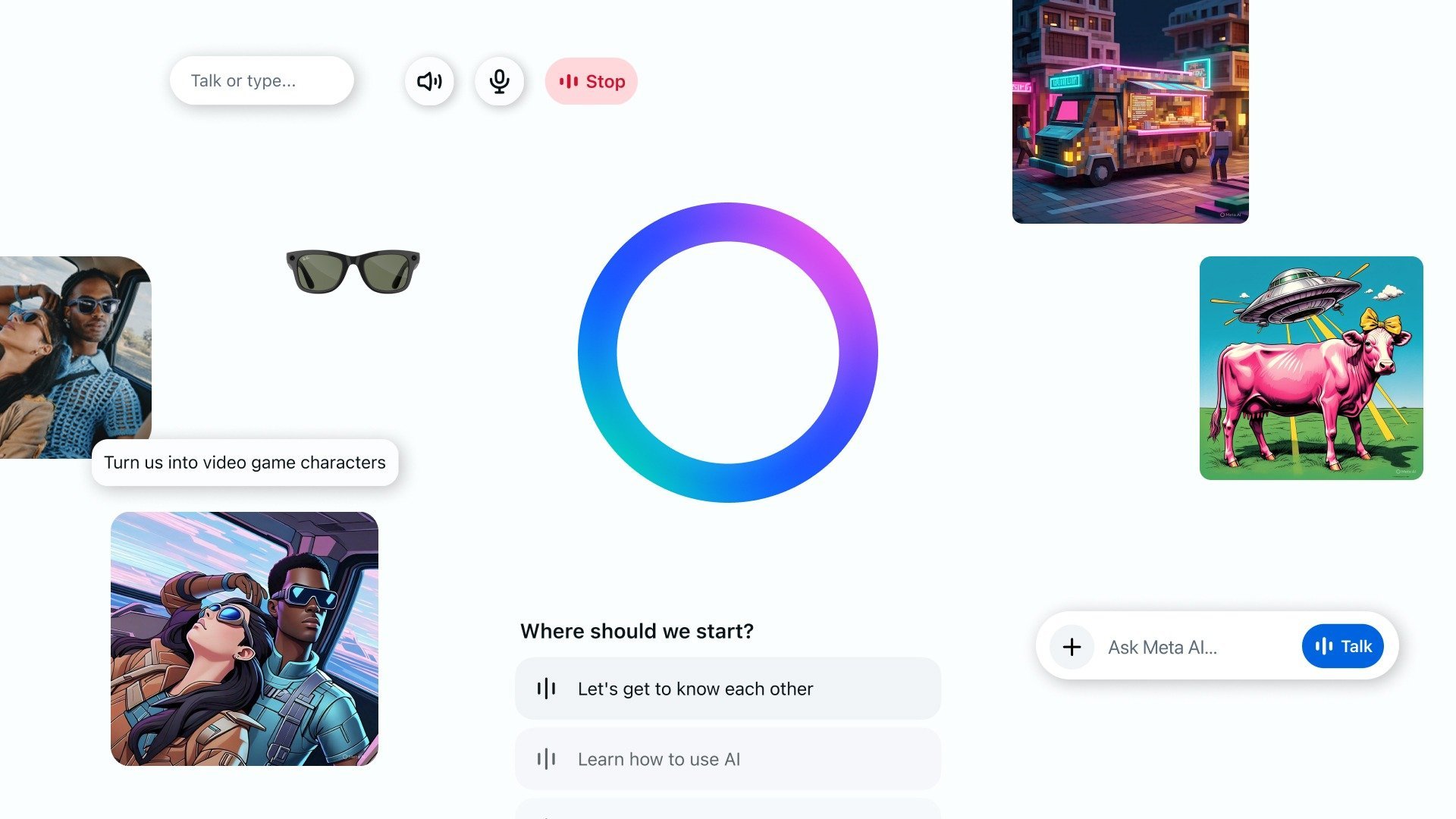 Η αυτόνομη εφαρμογή τεχνητής νοημοσύνης της Meta λειτουργεί ως ανταγωνιστής του ChatGPT, προσφέροντας τις αναμενόμενες λειτουργίες ενός AI βοηθού αλλά με μια σημαντική καινοτομία: ένα κοινωνικό feed ανακαλύψεων. Η εφαρμογή είναι διαθέσιμη για download από το Play Store του Android και το App Store του iPhone. Σύμφωνα με τον Connor Hayes, Αντιπρόεδρο προϊόντων της Meta, η νέα εφαρμογή Meta AI περιλαμβάνει ένα Discover feed που προσθέτει μια AI διάσταση στα κοινωνικά δίκτυα. Σε αυτό το feed, οι χρήστες μπορούν να δουν αλληλεπιδράσεις άλλων ανθρώπων με το Meta AI, συμπεριλαμβανομένων των φίλων τους από το Instagram και το Facebook, που έχουν επιλέξει να μοιραστούν. Οι χρήστες έχουν τη δυνατότητα να κάνουν like, να σχολιάσουν, να μοιραστούν ή να τροποποιήσουν αυτές τις AI κοινοποιήσεις. «Στόχος μας είναι να απομυθοποιήσουμε την τεχνητή νοημοσύνη και να δείξουμε στον κόσμο τις πραγματικές δυνατότητες που τους προσφέρει», δηλώνει ο Connor Hayes, Αντιπρόεδρος Προϊόντος της Meta. Η σύγκλιση των AI chatbots με τα κοινωνικά δίκτυα φαίνεται να αποτελεί μια αναδυόμενη τάση στον κλάδο. Το X του Elon Musk έχει ήδη ενσωματώσει το Grok, ενώ η OpenAI σχεδιάζει να προσθέσει ένα κοινωνικό feed στο ChatGPT. Η εφαρμογή Meta AI δίνει ιδιαίτερη έμφαση στη λειτουργία φωνής. Μια προαιρετική beta έκδοση καθιστά τη φωνή του Meta AI πιο φυσική στη συνομιλία, παρόμοια με την προηγμένη λειτουργία φωνής του ChatGPT, αν και η έκδοση της Meta δεν έχει προς το παρόν πρόσβαση σε πληροφορίες από το διαδίκτυο. Η προαιρετική λειτουργία φωνής βασίζεται στο ερευνητικό μοντέλο AI "full-duplex" που έχει δημοσιεύσει η Meta. Έχει σχεδιαστεί για να επιτρέπει "πλούσιο συγχρονισμό με τη μορφή γρήγορης και δυναμικής εναλλαγής ομιλίας, επικαλυπτόμενου λόγου και ανάδρασης". Κατά τη διάρκεια μιας σύντομης επίδειξης, υπήρχε αισθητή διαφορά στο επίπεδο προσωπικότητας που μετέδιδε η λειτουργία full-duplex σε σύγκριση με την τυπική λειτουργία φωνής. Αμφότερες οι λειτουργίες φωνής είναι διαθέσιμες αρχικά στις ΗΠΑ, τον Καναδά, την Αυστραλία και τη Νέα Ζηλανδία. Στις ΗΠΑ και τον Καναδά, η Meta χρησιμοποιεί πληροφορίες από τα προφίλ χρηστών του Facebook και Instagram για να εξατομικεύσει τις απαντήσεις του βοηθού της. Θεωρητικά, αυτό σημαίνει ότι ο τρόπος χρήσης και των δύο εφαρμογών θα επηρεάζει τα αποτελέσματα που λαμβάνουν οι χρήστες από το Meta AI. Όπως το ChatGPT, οι χρήστες μπορούν επίσης να δώσουν οδηγίες στο Meta AI να θυμάται συγκεκριμένες λεπτομέρειες για αυτούς. Η εφαρμογή τροφοδοτείται από μια προσαρμοσμένη από τη Meta έκδοση του Llama 4. Μέχρι στιγμής, οι περισσότεροι άνθρωποι έχουν έρθει σε επαφή με το Meta AI μέσω της ενσωμάτωσής του σε τμήματα του Instagram, του Facebook και του WhatsApp. Ο Hayes αναφέρει ότι το chatbot έχει φτάσει "σχεδόν" το ένα δισεκατομμύριο χρήστες με αυτόν τον τρόπο, αν και παραδέχεται ότι μια αυτόνομη εφαρμογή είναι "ο πιο διαισθητικός τρόπος αλληλεπίδρασης με έναν AI βοηθό". Ενδιαφέρον παρουσιάζει το γεγονός ότι η εφαρμογή Meta AI δεν κυκλοφορεί ως εντελώς νέα εφαρμογή, αλλά αντικαθιστά την υπάρχουσα εφαρμογή View για τα έξυπνα γυαλιά Meta Ray-Ban. Μια ειδική καρτέλα στο νέο περιβάλλον επιτρέπει την πρόσβαση στις ίδιες πληροφορίες με την προηγούμενη έκδοση της εφαρμογής View για τα γυαλιά. Σύμφωνα με τον Hayes, η Meta πήρε την απόφαση να συγχωνεύσει την εφαρμογή συνοδείας των γυαλιών με τον βοηθό της επειδή η εταιρεία βλέπει τον οδικό χάρτη προϊόντων AI ως "οδικό χάρτη software και hardware με την πάροδο του χρόνου". Τα γυαλιά Meta Ray-Ban χρησιμοποιούν ήδη AI για να αναγνωρίζουν τι βλέπετε και πρόσφατα προστέθηκε η δυνατότητα μετάφρασης μεταξύ γλωσσών σε πραγματικό χρόνο. Η Meta σχεδιάζει να κυκλοφορήσει αργότερα φέτος ένα πιο ακριβό ζευγάρι με μια μικρή οθόνη head-up display.
Η αυτόνομη εφαρμογή τεχνητής νοημοσύνης της Meta λειτουργεί ως ανταγωνιστής του ChatGPT, προσφέροντας τις αναμενόμενες λειτουργίες ενός AI βοηθού αλλά με μια σημαντική καινοτομία: ένα κοινωνικό feed ανακαλύψεων. Η εφαρμογή είναι διαθέσιμη για download από το Play Store του Android και το App Store του iPhone. Σύμφωνα με τον Connor Hayes, Αντιπρόεδρο προϊόντων της Meta, η νέα εφαρμογή Meta AI περιλαμβάνει ένα Discover feed που προσθέτει μια AI διάσταση στα κοινωνικά δίκτυα. Σε αυτό το feed, οι χρήστες μπορούν να δουν αλληλεπιδράσεις άλλων ανθρώπων με το Meta AI, συμπεριλαμβανομένων των φίλων τους από το Instagram και το Facebook, που έχουν επιλέξει να μοιραστούν. Οι χρήστες έχουν τη δυνατότητα να κάνουν like, να σχολιάσουν, να μοιραστούν ή να τροποποιήσουν αυτές τις AI κοινοποιήσεις. «Στόχος μας είναι να απομυθοποιήσουμε την τεχνητή νοημοσύνη και να δείξουμε στον κόσμο τις πραγματικές δυνατότητες που τους προσφέρει», δηλώνει ο Connor Hayes, Αντιπρόεδρος Προϊόντος της Meta. Η σύγκλιση των AI chatbots με τα κοινωνικά δίκτυα φαίνεται να αποτελεί μια αναδυόμενη τάση στον κλάδο. Το X του Elon Musk έχει ήδη ενσωματώσει το Grok, ενώ η OpenAI σχεδιάζει να προσθέσει ένα κοινωνικό feed στο ChatGPT. Η εφαρμογή Meta AI δίνει ιδιαίτερη έμφαση στη λειτουργία φωνής. Μια προαιρετική beta έκδοση καθιστά τη φωνή του Meta AI πιο φυσική στη συνομιλία, παρόμοια με την προηγμένη λειτουργία φωνής του ChatGPT, αν και η έκδοση της Meta δεν έχει προς το παρόν πρόσβαση σε πληροφορίες από το διαδίκτυο. Η προαιρετική λειτουργία φωνής βασίζεται στο ερευνητικό μοντέλο AI "full-duplex" που έχει δημοσιεύσει η Meta. Έχει σχεδιαστεί για να επιτρέπει "πλούσιο συγχρονισμό με τη μορφή γρήγορης και δυναμικής εναλλαγής ομιλίας, επικαλυπτόμενου λόγου και ανάδρασης". Κατά τη διάρκεια μιας σύντομης επίδειξης, υπήρχε αισθητή διαφορά στο επίπεδο προσωπικότητας που μετέδιδε η λειτουργία full-duplex σε σύγκριση με την τυπική λειτουργία φωνής. Αμφότερες οι λειτουργίες φωνής είναι διαθέσιμες αρχικά στις ΗΠΑ, τον Καναδά, την Αυστραλία και τη Νέα Ζηλανδία. Στις ΗΠΑ και τον Καναδά, η Meta χρησιμοποιεί πληροφορίες από τα προφίλ χρηστών του Facebook και Instagram για να εξατομικεύσει τις απαντήσεις του βοηθού της. Θεωρητικά, αυτό σημαίνει ότι ο τρόπος χρήσης και των δύο εφαρμογών θα επηρεάζει τα αποτελέσματα που λαμβάνουν οι χρήστες από το Meta AI. Όπως το ChatGPT, οι χρήστες μπορούν επίσης να δώσουν οδηγίες στο Meta AI να θυμάται συγκεκριμένες λεπτομέρειες για αυτούς. Η εφαρμογή τροφοδοτείται από μια προσαρμοσμένη από τη Meta έκδοση του Llama 4. Μέχρι στιγμής, οι περισσότεροι άνθρωποι έχουν έρθει σε επαφή με το Meta AI μέσω της ενσωμάτωσής του σε τμήματα του Instagram, του Facebook και του WhatsApp. Ο Hayes αναφέρει ότι το chatbot έχει φτάσει "σχεδόν" το ένα δισεκατομμύριο χρήστες με αυτόν τον τρόπο, αν και παραδέχεται ότι μια αυτόνομη εφαρμογή είναι "ο πιο διαισθητικός τρόπος αλληλεπίδρασης με έναν AI βοηθό". Ενδιαφέρον παρουσιάζει το γεγονός ότι η εφαρμογή Meta AI δεν κυκλοφορεί ως εντελώς νέα εφαρμογή, αλλά αντικαθιστά την υπάρχουσα εφαρμογή View για τα έξυπνα γυαλιά Meta Ray-Ban. Μια ειδική καρτέλα στο νέο περιβάλλον επιτρέπει την πρόσβαση στις ίδιες πληροφορίες με την προηγούμενη έκδοση της εφαρμογής View για τα γυαλιά. Σύμφωνα με τον Hayes, η Meta πήρε την απόφαση να συγχωνεύσει την εφαρμογή συνοδείας των γυαλιών με τον βοηθό της επειδή η εταιρεία βλέπει τον οδικό χάρτη προϊόντων AI ως "οδικό χάρτη software και hardware με την πάροδο του χρόνου". Τα γυαλιά Meta Ray-Ban χρησιμοποιούν ήδη AI για να αναγνωρίζουν τι βλέπετε και πρόσφατα προστέθηκε η δυνατότητα μετάφρασης μεταξύ γλωσσών σε πραγματικό χρόνο. Η Meta σχεδιάζει να κυκλοφορήσει αργότερα φέτος ένα πιο ακριβό ζευγάρι με μια μικρή οθόνη head-up display. -
 Η Meta ανακοίνωσε ότι ετοιμάζεται να εκπαιδεύσει την τεχνητή νοημοσύνη της με δεδομένα χρηστών της ΕΕ από εφαρμογές όπως το Facebook και το Instagram. Σύμφωνα με την εταιρεία, τα δεδομένα αυτά θα περιλαμβάνουν δημόσιες αναρτήσεις, σχόλια και το ιστορικό συνομιλιών με τη Meta AI, αλλά όχι "προσωπικά μηνύματα με φίλους και οικογένεια". Επιπλέον, η διαδικασία θα αφορά μόνο χρήστες άνω των 18 ετών. Η εταιρεία αναφέρει ότι θα αρχίσει να ενημερώνει τους χρήστες της στην ΕΕ σχετικά με την εκπαίδευση των συστημάτων της αυτή την εβδομάδα, μέσω ειδοποιήσεων στις εφαρμογές και email. Οι ενημερώσεις θα περιλαμβάνουν σύνδεσμο προς μια "φόρμα αντίρρησης" για όσους επιθυμούν να εξαιρεθούν από αυτή τη διαδικασία. Ο σύνδεσμος αυτός θα είναι διαθέσιμος και στην πολιτική απορρήτου της εταιρείας η οποία για την ώρα αναφέρει ότι με βάση τις εντολές των ρυθμιστικών αρχών, η εταιρεία εξακολουθεί να καθυστερεί τα σχέδιά της για την εκπαίδευση μοντέλων τεχνητής νοημοσύνης με δεδομένα χρηστών της ΕΕ. Συγκεκριμένα η Meta είχε αναστείλεί τα σχέδιά της για εκπαίδευση τεχνητής νοημοσύνης στην Ευρώπη από πέρυσι, μετά από αίτημα των Ιρλανδών ρυθμιστικών αρχών. Όπως υποστηρίζει η Meta, η εκπαίδευση των συστημάτων τεχνητής νοημοσύνης με δεδομένα χρηστών από την ΕΕ στοχεύει στη δημιουργία μοντέλων που αντικατοπτρίζουν τις περιοχές στις οποίες χρησιμοποιούνται. Αυτό περιλαμβάνει "από διαλέκτους και ιδιωματισμούς, μέχρι υπερτοπική γνώση και τους διαφορετικούς τρόπους με τους οποίους διάφορες χώρες χρησιμοποιούν το χιούμορ και τον σαρκασμό". Η εταιρεία προσθέτει ότι κάτι τέτοιο είναι ιδιαίτερα σημαντικό για το κείμενο, τη φωνή, το βίντεο και τις εικόνες που παράγονται από πολυτροπική (multimodal) τεχνητή νοημοσύνη. Η κίνηση αυτή ακολουθεί την περσινή ανακοίνωση της Meta ότι θα αρχίσει να εκπαιδεύει τα μοντέλα τεχνητής νοημοσύνης της με δεδομένα Βρετανών χρηστών, οι οποίοι, όπως και οι χρήστες της ΕΕ, έχουν περισσότερες εγγυήσεις προστασίας των προσωπικών τους δεδομένων στο διαδίκτυο σε σύγκριση με τους χρήστες στις ΗΠΑ. Ωστόσο, τα δεδομένα που θα αποκτήσει τώρα η Meta από τους χρήστες είναι ελάχιστα σε σύγκριση με αυτά που μπορεί να έχει ήδη συλλέξει. Η εταιρεία παραδέχτηκε πέρυσι ότι είχε εκπαιδεύσει συστήματα τεχνητής νοημοσύνης χρησιμοποιώντας όλα τα κείμενα και τις φωτογραφίες που είχαν δημοσιεύσει δημόσια ενήλικοι χρήστες του Facebook από το 2007. View full article
Η Meta ανακοίνωσε ότι ετοιμάζεται να εκπαιδεύσει την τεχνητή νοημοσύνη της με δεδομένα χρηστών της ΕΕ από εφαρμογές όπως το Facebook και το Instagram. Σύμφωνα με την εταιρεία, τα δεδομένα αυτά θα περιλαμβάνουν δημόσιες αναρτήσεις, σχόλια και το ιστορικό συνομιλιών με τη Meta AI, αλλά όχι "προσωπικά μηνύματα με φίλους και οικογένεια". Επιπλέον, η διαδικασία θα αφορά μόνο χρήστες άνω των 18 ετών. Η εταιρεία αναφέρει ότι θα αρχίσει να ενημερώνει τους χρήστες της στην ΕΕ σχετικά με την εκπαίδευση των συστημάτων της αυτή την εβδομάδα, μέσω ειδοποιήσεων στις εφαρμογές και email. Οι ενημερώσεις θα περιλαμβάνουν σύνδεσμο προς μια "φόρμα αντίρρησης" για όσους επιθυμούν να εξαιρεθούν από αυτή τη διαδικασία. Ο σύνδεσμος αυτός θα είναι διαθέσιμος και στην πολιτική απορρήτου της εταιρείας η οποία για την ώρα αναφέρει ότι με βάση τις εντολές των ρυθμιστικών αρχών, η εταιρεία εξακολουθεί να καθυστερεί τα σχέδιά της για την εκπαίδευση μοντέλων τεχνητής νοημοσύνης με δεδομένα χρηστών της ΕΕ. Συγκεκριμένα η Meta είχε αναστείλεί τα σχέδιά της για εκπαίδευση τεχνητής νοημοσύνης στην Ευρώπη από πέρυσι, μετά από αίτημα των Ιρλανδών ρυθμιστικών αρχών. Όπως υποστηρίζει η Meta, η εκπαίδευση των συστημάτων τεχνητής νοημοσύνης με δεδομένα χρηστών από την ΕΕ στοχεύει στη δημιουργία μοντέλων που αντικατοπτρίζουν τις περιοχές στις οποίες χρησιμοποιούνται. Αυτό περιλαμβάνει "από διαλέκτους και ιδιωματισμούς, μέχρι υπερτοπική γνώση και τους διαφορετικούς τρόπους με τους οποίους διάφορες χώρες χρησιμοποιούν το χιούμορ και τον σαρκασμό". Η εταιρεία προσθέτει ότι κάτι τέτοιο είναι ιδιαίτερα σημαντικό για το κείμενο, τη φωνή, το βίντεο και τις εικόνες που παράγονται από πολυτροπική (multimodal) τεχνητή νοημοσύνη. Η κίνηση αυτή ακολουθεί την περσινή ανακοίνωση της Meta ότι θα αρχίσει να εκπαιδεύει τα μοντέλα τεχνητής νοημοσύνης της με δεδομένα Βρετανών χρηστών, οι οποίοι, όπως και οι χρήστες της ΕΕ, έχουν περισσότερες εγγυήσεις προστασίας των προσωπικών τους δεδομένων στο διαδίκτυο σε σύγκριση με τους χρήστες στις ΗΠΑ. Ωστόσο, τα δεδομένα που θα αποκτήσει τώρα η Meta από τους χρήστες είναι ελάχιστα σε σύγκριση με αυτά που μπορεί να έχει ήδη συλλέξει. Η εταιρεία παραδέχτηκε πέρυσι ότι είχε εκπαιδεύσει συστήματα τεχνητής νοημοσύνης χρησιμοποιώντας όλα τα κείμενα και τις φωτογραφίες που είχαν δημοσιεύσει δημόσια ενήλικοι χρήστες του Facebook από το 2007. View full article -
 Σύμφωνα με την εταιρεία, τα δεδομένα αυτά θα περιλαμβάνουν δημόσιες αναρτήσεις, σχόλια και το ιστορικό συνομιλιών με τη Meta AI, αλλά όχι "προσωπικά μηνύματα με φίλους και οικογένεια". Επιπλέον, η διαδικασία θα αφορά μόνο χρήστες άνω των 18 ετών. Η εταιρεία αναφέρει ότι θα αρχίσει να ενημερώνει τους χρήστες της στην ΕΕ σχετικά με την εκπαίδευση των συστημάτων της αυτή την εβδομάδα, μέσω ειδοποιήσεων στις εφαρμογές και email. Οι ενημερώσεις θα περιλαμβάνουν σύνδεσμο προς μια "φόρμα αντίρρησης" για όσους επιθυμούν να εξαιρεθούν από αυτή τη διαδικασία. Ο σύνδεσμος αυτός θα είναι διαθέσιμος και στην πολιτική απορρήτου της εταιρείας η οποία για την ώρα αναφέρει ότι με βάση τις εντολές των ρυθμιστικών αρχών, η εταιρεία εξακολουθεί να καθυστερεί τα σχέδιά της για την εκπαίδευση μοντέλων τεχνητής νοημοσύνης με δεδομένα χρηστών της ΕΕ. Συγκεκριμένα η Meta είχε αναστείλεί τα σχέδιά της για εκπαίδευση τεχνητής νοημοσύνης στην Ευρώπη από πέρυσι, μετά από αίτημα των Ιρλανδών ρυθμιστικών αρχών. Όπως υποστηρίζει η Meta, η εκπαίδευση των συστημάτων τεχνητής νοημοσύνης με δεδομένα χρηστών από την ΕΕ στοχεύει στη δημιουργία μοντέλων που αντικατοπτρίζουν τις περιοχές στις οποίες χρησιμοποιούνται. Αυτό περιλαμβάνει "από διαλέκτους και ιδιωματισμούς, μέχρι υπερτοπική γνώση και τους διαφορετικούς τρόπους με τους οποίους διάφορες χώρες χρησιμοποιούν το χιούμορ και τον σαρκασμό". Η εταιρεία προσθέτει ότι κάτι τέτοιο είναι ιδιαίτερα σημαντικό για το κείμενο, τη φωνή, το βίντεο και τις εικόνες που παράγονται από πολυτροπική (multimodal) τεχνητή νοημοσύνη. Η κίνηση αυτή ακολουθεί την περσινή ανακοίνωση της Meta ότι θα αρχίσει να εκπαιδεύει τα μοντέλα τεχνητής νοημοσύνης της με δεδομένα Βρετανών χρηστών, οι οποίοι, όπως και οι χρήστες της ΕΕ, έχουν περισσότερες εγγυήσεις προστασίας των προσωπικών τους δεδομένων στο διαδίκτυο σε σύγκριση με τους χρήστες στις ΗΠΑ. Ωστόσο, τα δεδομένα που θα αποκτήσει τώρα η Meta από τους χρήστες είναι ελάχιστα σε σύγκριση με αυτά που μπορεί να έχει ήδη συλλέξει. Η εταιρεία παραδέχτηκε πέρυσι ότι είχε εκπαιδεύσει συστήματα τεχνητής νοημοσύνης χρησιμοποιώντας όλα τα κείμενα και τις φωτογραφίες που είχαν δημοσιεύσει δημόσια ενήλικοι χρήστες του Facebook από το 2007.
Σύμφωνα με την εταιρεία, τα δεδομένα αυτά θα περιλαμβάνουν δημόσιες αναρτήσεις, σχόλια και το ιστορικό συνομιλιών με τη Meta AI, αλλά όχι "προσωπικά μηνύματα με φίλους και οικογένεια". Επιπλέον, η διαδικασία θα αφορά μόνο χρήστες άνω των 18 ετών. Η εταιρεία αναφέρει ότι θα αρχίσει να ενημερώνει τους χρήστες της στην ΕΕ σχετικά με την εκπαίδευση των συστημάτων της αυτή την εβδομάδα, μέσω ειδοποιήσεων στις εφαρμογές και email. Οι ενημερώσεις θα περιλαμβάνουν σύνδεσμο προς μια "φόρμα αντίρρησης" για όσους επιθυμούν να εξαιρεθούν από αυτή τη διαδικασία. Ο σύνδεσμος αυτός θα είναι διαθέσιμος και στην πολιτική απορρήτου της εταιρείας η οποία για την ώρα αναφέρει ότι με βάση τις εντολές των ρυθμιστικών αρχών, η εταιρεία εξακολουθεί να καθυστερεί τα σχέδιά της για την εκπαίδευση μοντέλων τεχνητής νοημοσύνης με δεδομένα χρηστών της ΕΕ. Συγκεκριμένα η Meta είχε αναστείλεί τα σχέδιά της για εκπαίδευση τεχνητής νοημοσύνης στην Ευρώπη από πέρυσι, μετά από αίτημα των Ιρλανδών ρυθμιστικών αρχών. Όπως υποστηρίζει η Meta, η εκπαίδευση των συστημάτων τεχνητής νοημοσύνης με δεδομένα χρηστών από την ΕΕ στοχεύει στη δημιουργία μοντέλων που αντικατοπτρίζουν τις περιοχές στις οποίες χρησιμοποιούνται. Αυτό περιλαμβάνει "από διαλέκτους και ιδιωματισμούς, μέχρι υπερτοπική γνώση και τους διαφορετικούς τρόπους με τους οποίους διάφορες χώρες χρησιμοποιούν το χιούμορ και τον σαρκασμό". Η εταιρεία προσθέτει ότι κάτι τέτοιο είναι ιδιαίτερα σημαντικό για το κείμενο, τη φωνή, το βίντεο και τις εικόνες που παράγονται από πολυτροπική (multimodal) τεχνητή νοημοσύνη. Η κίνηση αυτή ακολουθεί την περσινή ανακοίνωση της Meta ότι θα αρχίσει να εκπαιδεύει τα μοντέλα τεχνητής νοημοσύνης της με δεδομένα Βρετανών χρηστών, οι οποίοι, όπως και οι χρήστες της ΕΕ, έχουν περισσότερες εγγυήσεις προστασίας των προσωπικών τους δεδομένων στο διαδίκτυο σε σύγκριση με τους χρήστες στις ΗΠΑ. Ωστόσο, τα δεδομένα που θα αποκτήσει τώρα η Meta από τους χρήστες είναι ελάχιστα σε σύγκριση με αυτά που μπορεί να έχει ήδη συλλέξει. Η εταιρεία παραδέχτηκε πέρυσι ότι είχε εκπαιδεύσει συστήματα τεχνητής νοημοσύνης χρησιμοποιώντας όλα τα κείμενα και τις φωτογραφίες που είχαν δημοσιεύσει δημόσια ενήλικοι χρήστες του Facebook από το 2007. -
Ένα από τα κορυφαία μοντέλα μεγάλης γλωσσικής τεχνητής νοημοσύνης πέρασε το τεστ Turing, ένα μακροχρόνιο βαρόμετρο για την ανθρωπόμορφη νοημοσύνη. Σύμφωνα με νέα προδημοσιευμένη μελέτη που αναμένει αξιολόγηση από ομότιμους, ερευνητές αναφέρουν ότι σε μια τριμερή έκδοση του τεστ Turing, όπου οι συμμετέχοντες συνομιλούν ταυτόχρονα με έναν άνθρωπο και μια τεχνητή νοημοσύνη και στη συνέχεια αξιολογούν ποιος είναι ποιος, το μοντέλο GPT-4.5 της OpenAI θεωρήθηκε άνθρωπος στο 73% των περιπτώσεων όταν είχε οδηγίες να υιοθετήσει συγκεκριμένο χαρακτήρα. Το ποσοστό αυτό είναι σημαντικά υψηλότερο από την τυχαία πιθανότητα του 50%, υποδηλώνοντας ότι το τεστ Turing έχει ξεπεραστεί κατά πολύ. Η έρευνα αξιολόγησε επίσης το μοντέλο LLama 3.1-405B της Meta, το μοντέλο GPT-4o της OpenAI και ένα πρώιμο chatbot γνωστό ως ELIZA που αναπτύχθηκε αρκετά χρόνια πριν. "Οι άνθρωποι δεν ήταν καλύτεροι από την τύχη στο να διακρίνουν ανθρώπους από το GPT-4.5 και το LLaMa (με την προτροπή προσωπικότητας)", έγραψε ο επικεφαλής συγγραφέας Cameron Jones, ερευνητής στο Εργαστήριο Γλώσσας και Γνώσης του UC San Diego, σε ανάρτηση στο X σχετικά με την εργασία. "Και το GPT 4.5 κρίθηκε ως άνθρωπος σημαντικά συχνότερα από τους πραγματικούς ανθρώπους!" Το τεστ Turing οφείλει την ονομασία του στον Βρετανό μαθηματικό και επιστήμονα υπολογιστών Alan Turing. Το 1950, ο Turing πρότεινε μια μέθοδο για την αξιολόγηση της νοημοσύνης μιας μηχανής, η οποία περιλάμβανε συνομιλίες κειμένου μεταξύ ενός ανθρώπου-αξιολογητή και δύο συνομιλητών που βρίσκονταν εκτός οπτικού πεδίου: μιας μηχανής και ενός άλλου ανθρώπου. Ο ίδιος ο Turing αναφερόταν σε αυτή τη διαδικασία ως "παιχνίδι μίμησης". Στην πρόσφατη μελέτη, οι ερευνητές διεξήγαγαν το περίφημο πείραμα σε μια διαδικτυακή πλατφόρμα. Για οκτώ γύρους, ένα δείγμα σχεδόν 300 συμμετεχόντων τοποθετήθηκε τυχαία είτε ως ανακριτής είτε ως ένας από τους δύο "μάρτυρες" που ανακρίνονται, με τον άλλο "μάρτυρα" να είναι ένα chatbot. Ένα βασικό σημείο εδώ είναι πώς προγραμματίστηκαν τα μοντέλα AI. Ένας τύπος ήταν η προτροπή "χωρίς προσωπικότητα", όπου η AI έλαβε μόνο βασικές οδηγίες. Για την προτροπή "προσωπικότητας", από την άλλη πλευρά, η AI ενημερώθηκε συγκεκριμένα να υιοθετήσει συγκεκριμένο χαρακτήρα, όπως ένα νεαρό άτομο με γνώσεις για το διαδίκτυο και τον πολιτισμό. Οι οδηγίες αυτές έκαναν τεράστια διαφορά. Χωρίς προτροπή προσωπικότητας, το GPT-4.5 πέτυχε συνολικό ποσοστό επιτυχίας μόλις 36%, σημαντικά χαμηλότερο από το 73% που θριάμβευσε στο Turing. Ως βάση, το GPT-4o, που τροφοδοτεί την τρέχουσα έκδοση του ChatGPT και έλαβε μόνο προτροπές χωρίς προσωπικότητα, πέτυχε ένα ακόμη λιγότερο πειστικό 21%. (Κάπως, το αρχαίο ELIZA ξεπέρασε οριακά το κορυφαίο μοντέλο της OpenAI με ποσοστό επιτυχίας 23%.) Ωστόσο, όπως επισημαίνει ο Jones, τα αποτελέσματα δεν σημαίνουν απαραίτητα ότι τα LLMs είναι ευφυή όπως οι άνθρωποι. "Νομίζω ότι είναι μια πολύ περίπλοκη ερώτηση...", έγραψε ο Jones στο Twitter. "Αλλά γενικά πιστεύω ότι αυτό θα πρέπει να αξιολογηθεί ως ένα από τα πολλά πρόσθετα στοιχεία για το είδος της νοημοσύνης που εμφανίζουν τα LLMs." "Πιστεύω ότι τα αποτελέσματα παρέχουν περισσότερες αποδείξεις ότι τα LLMs θα μπορούσαν να υποκαταστήσουν τους ανθρώπους σε σύντομες αλληλεπιδράσεις χωρίς κανείς να μπορεί να το καταλάβει", πρόσθεσε. "Αυτό θα μπορούσε δυνητικά να οδηγήσει σε αυτοματοποίηση θέσεων εργασίας, βελτιωμένες επιθέσεις κοινωνικής μηχανικής και γενικότερη κοινωνική αναστάτωση." Ο Jones κλείνει τονίζοντας ότι το τεστ Turing δεν βάζει μόνο τις μηχανές κάτω από το μικροσκόπιο - αντικατοπτρίζει επίσης τις συνεχώς εξελισσόμενες αντιλήψεις των ανθρώπων για την τεχνολογία. Έτσι τα αποτελέσματα δεν είναι στατικά: ίσως καθώς το κοινό εξοικειώνεται περισσότερο με την αλληλεπίδραση με την τεχνητή νοημοσύνη, θα γίνει καλύτερο και στον εντοπισμό της. Διαβάστε ολόκληρο το άρθρο
-
Η Meta κυκλοφόρησε τα δύο πρώτα μοντέλα από τη σουίτα πολυτροπικών μοντέλων Llama 4: το Llama 4 Scout και το Llama 4 Maverick, ενώ ανακοίνωσε και το επερχόμενο Llama 4 Behemoth. Όπως αναφέρε στο blog της εταιρείας, το Maverick είναι "ο ακούραστης εργάτης" των δύο και διαπρέπει στην κατανόηση εικόνας και κειμένου για "γενικές περιπτώσεις χρήσης βοηθού και συνομιλίας", ενώ το μικρότερο μοντέλο Scout θα μπορούσε να αντιμετωπίσει θέματα όπως "συνοψίσεις πολλαπλών εγγράφων, ανάλυση εκτεταμένης δραστηριότητας χρήστη για εξατομικευμένες εργασίες και συλλογισμό σε τεράστιες βάσεις κώδικα". Η εταιρεία παρουσίασε επίσης το Llama 4 Behemoth, ένα επερχόμενο μοντέλο που, όπως αναφέρει, είναι "μεταξύ των εξυπνότερων LLM στον κόσμο". Ο Διευθύνων Σύμβουλος Mark Zuckerberg δήλωσε ότι θα ακούσουμε για ένα τέταρτο μοντέλο, το Llama 4 Reasoning, "τον επόμενο μήνα". Τόσο το Maverick όσο και το Scout είναι διαθέσιμα για λήψη από τον ιστότοπο του Llama και το Hugging Face, και έχουν προστεθεί στο Meta AI, συμπεριλαμβανομένων των εφαρμογών WhatsApp, Messenger και Instagram DMs. Σύμφωνα με τη Meta, το Scout διαθέτει 17 δισεκατομμύρια ενεργές παραμέτρους με 16 ειδικούς. Όπως ανέφερε ο Zuckerberg, "Είναι εξαιρετικά γρήγορο, εγγενώς πολυτροπικό και διαθέτει ένα κορυφαίο στον κλάδο, σχεδόν άπειρο μήκος πλαισίου 10 εκατομμυρίων tokens, και είναι σχεδιασμένο να λειτουργεί σε μία μόνο GPU". Το Maverick από την άλλη πλευρά έχει 17 δισεκατομμύρια ενεργές παραμέτρους με 128 ειδικούς. Η εταιρεία υποστηρίζει ότι ξεπερνά ανταγωνιστές όπως το GPT-4o και το Gemini 2.0 σε δοκιμές κώδικα, συλλογισμού, πολυγλωσσικότητας, μακρού πλαισίου και εικόνας, και είναι εφάμιλλο του DeepSeek v3.1 σε συλλογισμό και κωδικοποίηση. Ο Zuckerberg ήδη χαρακτηρίζει το επερχόμενο μοντέλο Behemoth, το οποίο βρίσκεται ακόμη σε φάση εκπαίδευσης, ως "το υψηλότερης απόδοσης βασικό μοντέλο στον κόσμο", με 288 δισεκατομμύρια ενεργές παραμέτρους, σύμφωνα με την εταιρεία. Αν και το Behemoth δεν είναι ακόμη διαθέσιμο, είναι πιθανό να ακούσουμε περισσότερα για αυτό και το μοντέλο Reasoning σύντομα. Το μεγάλο συνέδριο προγραμματιστών AI της Meta, το LlamaCon, είναι μόλις λίγες εβδομάδες μακριά, όπου αναμένεται να παρουσιαστούν περισσότερες λεπτομέρειες. Τα νέα μοντέλα της Meta αποτελούν σημαντική εξέλιξη στον τομέα της τεχνητής νοημοσύνης, καθώς προσφέρουν προηγμένες δυνατότητες επεξεργασίας εικόνας και κειμένου, ενώ παράλληλα είναι προσβάσιμα μέσω πολλαπλών πλατφορμών της εταιρείας, διευρύνοντας έτσι τις δυνατότητες χρήσης της τεχνολογίας AI σε καθημερινές εφαρμογές. Διαβάστε ολόκληρο το άρθρο
-
 Σύμφωνα με νέα προδημοσιευμένη μελέτη που αναμένει αξιολόγηση από ομότιμους, ερευνητές αναφέρουν ότι σε μια τριμερή έκδοση του τεστ Turing, όπου οι συμμετέχοντες συνομιλούν ταυτόχρονα με έναν άνθρωπο και μια τεχνητή νοημοσύνη και στη συνέχεια αξιολογούν ποιος είναι ποιος, το μοντέλο GPT-4.5 της OpenAI θεωρήθηκε άνθρωπος στο 73% των περιπτώσεων όταν είχε οδηγίες να υιοθετήσει συγκεκριμένο χαρακτήρα. Το ποσοστό αυτό είναι σημαντικά υψηλότερο από την τυχαία πιθανότητα του 50%, υποδηλώνοντας ότι το τεστ Turing έχει ξεπεραστεί κατά πολύ. Η έρευνα αξιολόγησε επίσης το μοντέλο LLama 3.1-405B της Meta, το μοντέλο GPT-4o της OpenAI και ένα πρώιμο chatbot γνωστό ως ELIZA που αναπτύχθηκε αρκετά χρόνια πριν. "Οι άνθρωποι δεν ήταν καλύτεροι από την τύχη στο να διακρίνουν ανθρώπους από το GPT-4.5 και το LLaMa (με την προτροπή προσωπικότητας)", έγραψε ο επικεφαλής συγγραφέας Cameron Jones, ερευνητής στο Εργαστήριο Γλώσσας και Γνώσης του UC San Diego, σε ανάρτηση στο X σχετικά με την εργασία. "Και το GPT 4.5 κρίθηκε ως άνθρωπος σημαντικά συχνότερα από τους πραγματικούς ανθρώπους!" Το τεστ Turing οφείλει την ονομασία του στον Βρετανό μαθηματικό και επιστήμονα υπολογιστών Alan Turing. Το 1950, ο Turing πρότεινε μια μέθοδο για την αξιολόγηση της νοημοσύνης μιας μηχανής, η οποία περιλάμβανε συνομιλίες κειμένου μεταξύ ενός ανθρώπου-αξιολογητή και δύο συνομιλητών που βρίσκονταν εκτός οπτικού πεδίου: μιας μηχανής και ενός άλλου ανθρώπου. Ο ίδιος ο Turing αναφερόταν σε αυτή τη διαδικασία ως "παιχνίδι μίμησης". Στην πρόσφατη μελέτη, οι ερευνητές διεξήγαγαν το περίφημο πείραμα σε μια διαδικτυακή πλατφόρμα. Για οκτώ γύρους, ένα δείγμα σχεδόν 300 συμμετεχόντων τοποθετήθηκε τυχαία είτε ως ανακριτής είτε ως ένας από τους δύο "μάρτυρες" που ανακρίνονται, με τον άλλο "μάρτυρα" να είναι ένα chatbot. Ένα βασικό σημείο εδώ είναι πώς προγραμματίστηκαν τα μοντέλα AI. Ένας τύπος ήταν η προτροπή "χωρίς προσωπικότητα", όπου η AI έλαβε μόνο βασικές οδηγίες. Για την προτροπή "προσωπικότητας", από την άλλη πλευρά, η AI ενημερώθηκε συγκεκριμένα να υιοθετήσει συγκεκριμένο χαρακτήρα, όπως ένα νεαρό άτομο με γνώσεις για το διαδίκτυο και τον πολιτισμό. Οι οδηγίες αυτές έκαναν τεράστια διαφορά. Χωρίς προτροπή προσωπικότητας, το GPT-4.5 πέτυχε συνολικό ποσοστό επιτυχίας μόλις 36%, σημαντικά χαμηλότερο από το 73% που θριάμβευσε στο Turing. Ως βάση, το GPT-4o, που τροφοδοτεί την τρέχουσα έκδοση του ChatGPT και έλαβε μόνο προτροπές χωρίς προσωπικότητα, πέτυχε ένα ακόμη λιγότερο πειστικό 21%. (Κάπως, το αρχαίο ELIZA ξεπέρασε οριακά το κορυφαίο μοντέλο της OpenAI με ποσοστό επιτυχίας 23%.) Ωστόσο, όπως επισημαίνει ο Jones, τα αποτελέσματα δεν σημαίνουν απαραίτητα ότι τα LLMs είναι ευφυή όπως οι άνθρωποι. "Νομίζω ότι είναι μια πολύ περίπλοκη ερώτηση...", έγραψε ο Jones στο Twitter. "Αλλά γενικά πιστεύω ότι αυτό θα πρέπει να αξιολογηθεί ως ένα από τα πολλά πρόσθετα στοιχεία για το είδος της νοημοσύνης που εμφανίζουν τα LLMs." "Πιστεύω ότι τα αποτελέσματα παρέχουν περισσότερες αποδείξεις ότι τα LLMs θα μπορούσαν να υποκαταστήσουν τους ανθρώπους σε σύντομες αλληλεπιδράσεις χωρίς κανείς να μπορεί να το καταλάβει", πρόσθεσε. "Αυτό θα μπορούσε δυνητικά να οδηγήσει σε αυτοματοποίηση θέσεων εργασίας, βελτιωμένες επιθέσεις κοινωνικής μηχανικής και γενικότερη κοινωνική αναστάτωση." Ο Jones κλείνει τονίζοντας ότι το τεστ Turing δεν βάζει μόνο τις μηχανές κάτω από το μικροσκόπιο - αντικατοπτρίζει επίσης τις συνεχώς εξελισσόμενες αντιλήψεις των ανθρώπων για την τεχνολογία. Έτσι τα αποτελέσματα δεν είναι στατικά: ίσως καθώς το κοινό εξοικειώνεται περισσότερο με την αλληλεπίδραση με την τεχνητή νοημοσύνη, θα γίνει καλύτερο και στον εντοπισμό της.
Σύμφωνα με νέα προδημοσιευμένη μελέτη που αναμένει αξιολόγηση από ομότιμους, ερευνητές αναφέρουν ότι σε μια τριμερή έκδοση του τεστ Turing, όπου οι συμμετέχοντες συνομιλούν ταυτόχρονα με έναν άνθρωπο και μια τεχνητή νοημοσύνη και στη συνέχεια αξιολογούν ποιος είναι ποιος, το μοντέλο GPT-4.5 της OpenAI θεωρήθηκε άνθρωπος στο 73% των περιπτώσεων όταν είχε οδηγίες να υιοθετήσει συγκεκριμένο χαρακτήρα. Το ποσοστό αυτό είναι σημαντικά υψηλότερο από την τυχαία πιθανότητα του 50%, υποδηλώνοντας ότι το τεστ Turing έχει ξεπεραστεί κατά πολύ. Η έρευνα αξιολόγησε επίσης το μοντέλο LLama 3.1-405B της Meta, το μοντέλο GPT-4o της OpenAI και ένα πρώιμο chatbot γνωστό ως ELIZA που αναπτύχθηκε αρκετά χρόνια πριν. "Οι άνθρωποι δεν ήταν καλύτεροι από την τύχη στο να διακρίνουν ανθρώπους από το GPT-4.5 και το LLaMa (με την προτροπή προσωπικότητας)", έγραψε ο επικεφαλής συγγραφέας Cameron Jones, ερευνητής στο Εργαστήριο Γλώσσας και Γνώσης του UC San Diego, σε ανάρτηση στο X σχετικά με την εργασία. "Και το GPT 4.5 κρίθηκε ως άνθρωπος σημαντικά συχνότερα από τους πραγματικούς ανθρώπους!" Το τεστ Turing οφείλει την ονομασία του στον Βρετανό μαθηματικό και επιστήμονα υπολογιστών Alan Turing. Το 1950, ο Turing πρότεινε μια μέθοδο για την αξιολόγηση της νοημοσύνης μιας μηχανής, η οποία περιλάμβανε συνομιλίες κειμένου μεταξύ ενός ανθρώπου-αξιολογητή και δύο συνομιλητών που βρίσκονταν εκτός οπτικού πεδίου: μιας μηχανής και ενός άλλου ανθρώπου. Ο ίδιος ο Turing αναφερόταν σε αυτή τη διαδικασία ως "παιχνίδι μίμησης". Στην πρόσφατη μελέτη, οι ερευνητές διεξήγαγαν το περίφημο πείραμα σε μια διαδικτυακή πλατφόρμα. Για οκτώ γύρους, ένα δείγμα σχεδόν 300 συμμετεχόντων τοποθετήθηκε τυχαία είτε ως ανακριτής είτε ως ένας από τους δύο "μάρτυρες" που ανακρίνονται, με τον άλλο "μάρτυρα" να είναι ένα chatbot. Ένα βασικό σημείο εδώ είναι πώς προγραμματίστηκαν τα μοντέλα AI. Ένας τύπος ήταν η προτροπή "χωρίς προσωπικότητα", όπου η AI έλαβε μόνο βασικές οδηγίες. Για την προτροπή "προσωπικότητας", από την άλλη πλευρά, η AI ενημερώθηκε συγκεκριμένα να υιοθετήσει συγκεκριμένο χαρακτήρα, όπως ένα νεαρό άτομο με γνώσεις για το διαδίκτυο και τον πολιτισμό. Οι οδηγίες αυτές έκαναν τεράστια διαφορά. Χωρίς προτροπή προσωπικότητας, το GPT-4.5 πέτυχε συνολικό ποσοστό επιτυχίας μόλις 36%, σημαντικά χαμηλότερο από το 73% που θριάμβευσε στο Turing. Ως βάση, το GPT-4o, που τροφοδοτεί την τρέχουσα έκδοση του ChatGPT και έλαβε μόνο προτροπές χωρίς προσωπικότητα, πέτυχε ένα ακόμη λιγότερο πειστικό 21%. (Κάπως, το αρχαίο ELIZA ξεπέρασε οριακά το κορυφαίο μοντέλο της OpenAI με ποσοστό επιτυχίας 23%.) Ωστόσο, όπως επισημαίνει ο Jones, τα αποτελέσματα δεν σημαίνουν απαραίτητα ότι τα LLMs είναι ευφυή όπως οι άνθρωποι. "Νομίζω ότι είναι μια πολύ περίπλοκη ερώτηση...", έγραψε ο Jones στο Twitter. "Αλλά γενικά πιστεύω ότι αυτό θα πρέπει να αξιολογηθεί ως ένα από τα πολλά πρόσθετα στοιχεία για το είδος της νοημοσύνης που εμφανίζουν τα LLMs." "Πιστεύω ότι τα αποτελέσματα παρέχουν περισσότερες αποδείξεις ότι τα LLMs θα μπορούσαν να υποκαταστήσουν τους ανθρώπους σε σύντομες αλληλεπιδράσεις χωρίς κανείς να μπορεί να το καταλάβει", πρόσθεσε. "Αυτό θα μπορούσε δυνητικά να οδηγήσει σε αυτοματοποίηση θέσεων εργασίας, βελτιωμένες επιθέσεις κοινωνικής μηχανικής και γενικότερη κοινωνική αναστάτωση." Ο Jones κλείνει τονίζοντας ότι το τεστ Turing δεν βάζει μόνο τις μηχανές κάτω από το μικροσκόπιο - αντικατοπτρίζει επίσης τις συνεχώς εξελισσόμενες αντιλήψεις των ανθρώπων για την τεχνολογία. Έτσι τα αποτελέσματα δεν είναι στατικά: ίσως καθώς το κοινό εξοικειώνεται περισσότερο με την αλληλεπίδραση με την τεχνητή νοημοσύνη, θα γίνει καλύτερο και στον εντοπισμό της. -
 Όπως αναφέρε στο blog της εταιρείας, το Maverick είναι "ο ακούραστης εργάτης" των δύο και διαπρέπει στην κατανόηση εικόνας και κειμένου για "γενικές περιπτώσεις χρήσης βοηθού και συνομιλίας", ενώ το μικρότερο μοντέλο Scout θα μπορούσε να αντιμετωπίσει θέματα όπως "συνοψίσεις πολλαπλών εγγράφων, ανάλυση εκτεταμένης δραστηριότητας χρήστη για εξατομικευμένες εργασίες και συλλογισμό σε τεράστιες βάσεις κώδικα". Η εταιρεία παρουσίασε επίσης το Llama 4 Behemoth, ένα επερχόμενο μοντέλο που, όπως αναφέρει, είναι "μεταξύ των εξυπνότερων LLM στον κόσμο". Ο Διευθύνων Σύμβουλος Mark Zuckerberg δήλωσε ότι θα ακούσουμε για ένα τέταρτο μοντέλο, το Llama 4 Reasoning, "τον επόμενο μήνα". Τόσο το Maverick όσο και το Scout είναι διαθέσιμα για λήψη από τον ιστότοπο του Llama και το Hugging Face, και έχουν προστεθεί στο Meta AI, συμπεριλαμβανομένων των εφαρμογών WhatsApp, Messenger και Instagram DMs. Σύμφωνα με τη Meta, το Scout διαθέτει 17 δισεκατομμύρια ενεργές παραμέτρους με 16 ειδικούς. Όπως ανέφερε ο Zuckerberg, "Είναι εξαιρετικά γρήγορο, εγγενώς πολυτροπικό και διαθέτει ένα κορυφαίο στον κλάδο, σχεδόν άπειρο μήκος πλαισίου 10 εκατομμυρίων tokens, και είναι σχεδιασμένο να λειτουργεί σε μία μόνο GPU". Το Maverick από την άλλη πλευρά έχει 17 δισεκατομμύρια ενεργές παραμέτρους με 128 ειδικούς. Η εταιρεία υποστηρίζει ότι ξεπερνά ανταγωνιστές όπως το GPT-4o και το Gemini 2.0 σε δοκιμές κώδικα, συλλογισμού, πολυγλωσσικότητας, μακρού πλαισίου και εικόνας, και είναι εφάμιλλο του DeepSeek v3.1 σε συλλογισμό και κωδικοποίηση. Ο Zuckerberg ήδη χαρακτηρίζει το επερχόμενο μοντέλο Behemoth, το οποίο βρίσκεται ακόμη σε φάση εκπαίδευσης, ως "το υψηλότερης απόδοσης βασικό μοντέλο στον κόσμο", με 288 δισεκατομμύρια ενεργές παραμέτρους, σύμφωνα με την εταιρεία. Αν και το Behemoth δεν είναι ακόμη διαθέσιμο, είναι πιθανό να ακούσουμε περισσότερα για αυτό και το μοντέλο Reasoning σύντομα. Το μεγάλο συνέδριο προγραμματιστών AI της Meta, το LlamaCon, είναι μόλις λίγες εβδομάδες μακριά, όπου αναμένεται να παρουσιαστούν περισσότερες λεπτομέρειες. Τα νέα μοντέλα της Meta αποτελούν σημαντική εξέλιξη στον τομέα της τεχνητής νοημοσύνης, καθώς προσφέρουν προηγμένες δυνατότητες επεξεργασίας εικόνας και κειμένου, ενώ παράλληλα είναι προσβάσιμα μέσω πολλαπλών πλατφορμών της εταιρείας, διευρύνοντας έτσι τις δυνατότητες χρήσης της τεχνολογίας AI σε καθημερινές εφαρμογές.
Όπως αναφέρε στο blog της εταιρείας, το Maverick είναι "ο ακούραστης εργάτης" των δύο και διαπρέπει στην κατανόηση εικόνας και κειμένου για "γενικές περιπτώσεις χρήσης βοηθού και συνομιλίας", ενώ το μικρότερο μοντέλο Scout θα μπορούσε να αντιμετωπίσει θέματα όπως "συνοψίσεις πολλαπλών εγγράφων, ανάλυση εκτεταμένης δραστηριότητας χρήστη για εξατομικευμένες εργασίες και συλλογισμό σε τεράστιες βάσεις κώδικα". Η εταιρεία παρουσίασε επίσης το Llama 4 Behemoth, ένα επερχόμενο μοντέλο που, όπως αναφέρει, είναι "μεταξύ των εξυπνότερων LLM στον κόσμο". Ο Διευθύνων Σύμβουλος Mark Zuckerberg δήλωσε ότι θα ακούσουμε για ένα τέταρτο μοντέλο, το Llama 4 Reasoning, "τον επόμενο μήνα". Τόσο το Maverick όσο και το Scout είναι διαθέσιμα για λήψη από τον ιστότοπο του Llama και το Hugging Face, και έχουν προστεθεί στο Meta AI, συμπεριλαμβανομένων των εφαρμογών WhatsApp, Messenger και Instagram DMs. Σύμφωνα με τη Meta, το Scout διαθέτει 17 δισεκατομμύρια ενεργές παραμέτρους με 16 ειδικούς. Όπως ανέφερε ο Zuckerberg, "Είναι εξαιρετικά γρήγορο, εγγενώς πολυτροπικό και διαθέτει ένα κορυφαίο στον κλάδο, σχεδόν άπειρο μήκος πλαισίου 10 εκατομμυρίων tokens, και είναι σχεδιασμένο να λειτουργεί σε μία μόνο GPU". Το Maverick από την άλλη πλευρά έχει 17 δισεκατομμύρια ενεργές παραμέτρους με 128 ειδικούς. Η εταιρεία υποστηρίζει ότι ξεπερνά ανταγωνιστές όπως το GPT-4o και το Gemini 2.0 σε δοκιμές κώδικα, συλλογισμού, πολυγλωσσικότητας, μακρού πλαισίου και εικόνας, και είναι εφάμιλλο του DeepSeek v3.1 σε συλλογισμό και κωδικοποίηση. Ο Zuckerberg ήδη χαρακτηρίζει το επερχόμενο μοντέλο Behemoth, το οποίο βρίσκεται ακόμη σε φάση εκπαίδευσης, ως "το υψηλότερης απόδοσης βασικό μοντέλο στον κόσμο", με 288 δισεκατομμύρια ενεργές παραμέτρους, σύμφωνα με την εταιρεία. Αν και το Behemoth δεν είναι ακόμη διαθέσιμο, είναι πιθανό να ακούσουμε περισσότερα για αυτό και το μοντέλο Reasoning σύντομα. Το μεγάλο συνέδριο προγραμματιστών AI της Meta, το LlamaCon, είναι μόλις λίγες εβδομάδες μακριά, όπου αναμένεται να παρουσιαστούν περισσότερες λεπτομέρειες. Τα νέα μοντέλα της Meta αποτελούν σημαντική εξέλιξη στον τομέα της τεχνητής νοημοσύνης, καθώς προσφέρουν προηγμένες δυνατότητες επεξεργασίας εικόνας και κειμένου, ενώ παράλληλα είναι προσβάσιμα μέσω πολλαπλών πλατφορμών της εταιρείας, διευρύνοντας έτσι τις δυνατότητες χρήσης της τεχνολογίας AI σε καθημερινές εφαρμογές.










